AI-powered search & chat for Data / Computer Science Students

11.1. Array API support (experimental)
The Array API specification defines a standard API for all array manipulation libraries with a NumPy-like API. Some scikit-learn estimators that primarily rely on NumPy (as opposed to using Cython)......
Read more at Scikit-learn User Guide
9. Model persistence
After training a scikit-learn model, it is desirable to have a way to persist the model for future use without having to retrain. The following sections give you some hints on how to persist a scik......
Read more at Scikit-learn User Guide
1.1. Linear Models
The following are a set of methods intended for regression in which the target value is expected to be a linear combination of the features. In mathematical notation, if\hat{y} is the predicted val......
Read more at Scikit-learn User Guide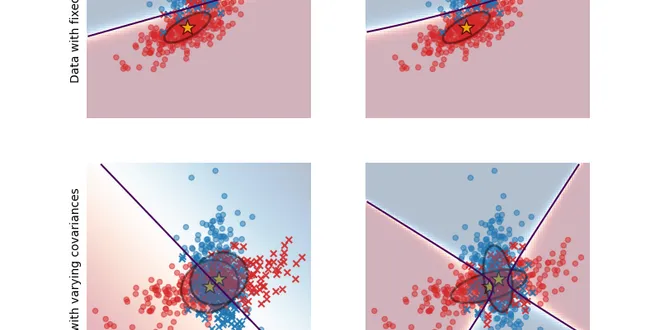
1.2. Linear and Quadratic Discriminant Analysis
Linear Discriminant Analysis ( LinearDiscriminantAnalysis) and Quadratic Discriminant Analysis ( QuadraticDiscriminantAnalysis) are two classic classifiers, with, as their names suggest, a linear a......
Read more at Scikit-learn User Guide
1.3. Kernel ridge regression
Kernel ridge regression (KRR)[M2012] combines Ridge regression and classification(linear least squares with l2-norm regularization) with the kernel trick. It thus learns a linear function in the sp......
Read more at Scikit-learn User Guide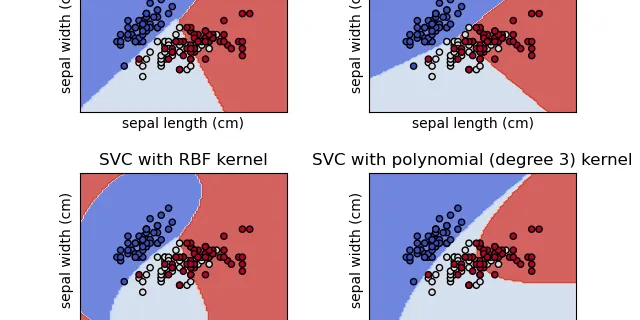
1.4. Support Vector Machines
Support vector machines (SVMs) are a set of supervised learning methods used for classification, regression and outliers detection. The advantages of support vector machines are: Effective in high ......
Read more at Scikit-learn User Guide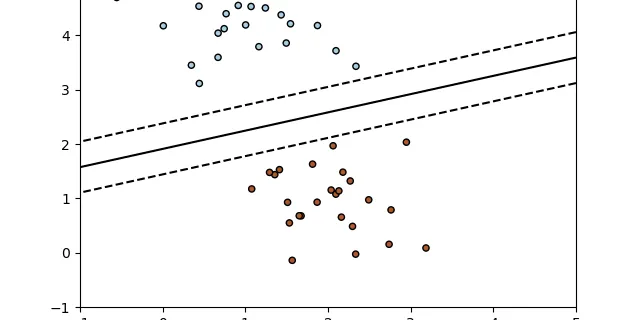
1.5. Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) is a simple yet very efficient approach to fitting linear classifiers and regressors under convex loss functions such as (linear) Support Vector Machines and Logis......
Read more at Scikit-learn User Guide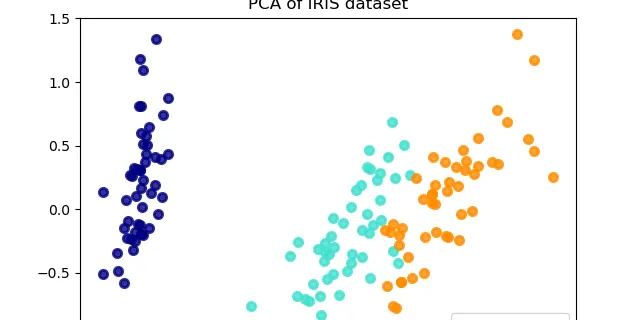
2.5. Decomposing signals in components (matrix factorization problems)
Principal component analysis (PCA): Exact PCA and probabilistic interpretation: PCA is used to decompose a multivariate dataset in a set of successive orthogonal components that explain a maximum a......
Read more at Scikit-learn User Guide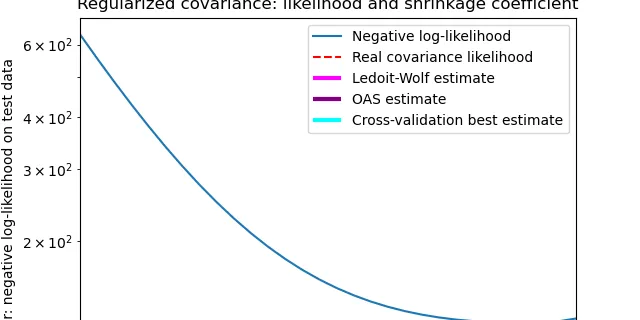
2.6. Covariance estimation
Many statistical problems require the estimation of a population’s covariance matrix, which can be seen as an estimation of data set scatter plot shape. Most of the time, such an estimation has to ......
Read more at Scikit-learn User Guide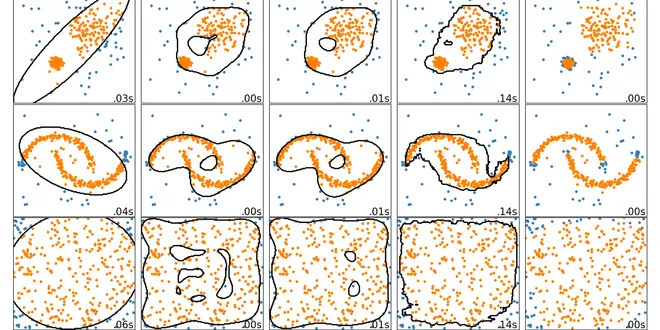
2.7. Novelty and Outlier Detection
Many applications require being able to decide whether a new observation belongs to the same distribution as existing observations (it is an inlier), or should be considered as different (it is an ......
Read more at Scikit-learn User Guide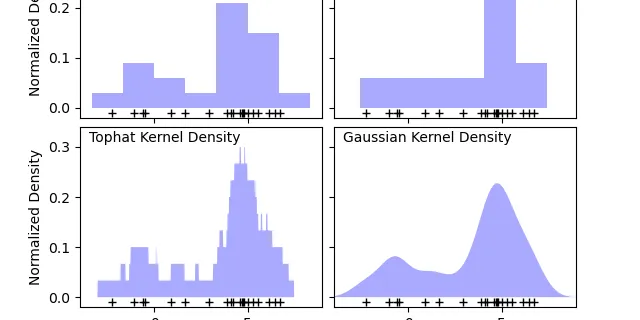
2.8. Density Estimation
Density estimation walks the line between unsupervised learning, feature engineering, and data modeling. Some of the most popular and useful density estimation techniques are mixture models such as......
Read more at Scikit-learn User Guide
2.9. Neural network models (unsupervised)
Restricted Boltzmann machines: Restricted Boltzmann machines (RBM) are unsupervised nonlinear feature learners based on a probabilistic model. The features extracted by an RBM or a hierarchy of RBM......
Read more at Scikit-learn User Guide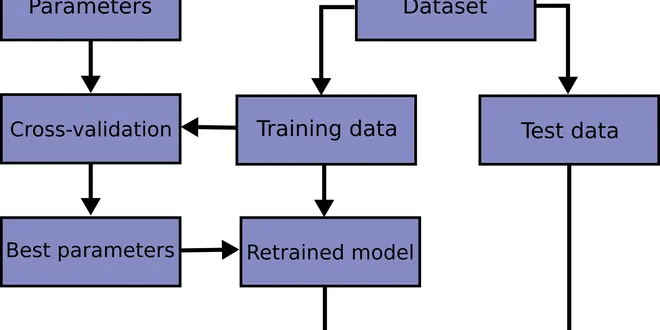
3.1. Cross-validation: evaluating estimator performance
Learning the parameters of a prediction function and testing it on the same data is a methodological mistake: a model that would just repeat the labels of the samples that it has just seen would ha......
Read more at Scikit-learn User Guide
3.2. Tuning the hyper-parameters of an estimator
Hyper-parameters are parameters that are not directly learnt within estimators. In scikit-learn they are passed as arguments to the constructor of the estimator classes. Typical examples include C,......
Read more at Scikit-learn User Guide
3.3. Metrics and scoring: quantifying the quality of predictions
There are 3 different APIs for evaluating the quality of a model’s predictions: Estimator score method: Estimators have a score method providing a default evaluation criterion for the problem they ......
Read more at Scikit-learn User Guide
3.4. Validation curves: plotting scores to evaluate models
Every estimator has its advantages and drawbacks. Its generalization error can be decomposed in terms of bias, variance and noise. The bias of an estimator is its average error for different traini......
Read more at Scikit-learn User Guide
4.1. Partial Dependence and Individual Conditional Expectation plots
Partial dependence plots (PDP) and individual conditional expectation (ICE) plots can be used to visualize and analyze interaction between the target response 1 and a set of input features of inter......
Read more at Scikit-learn User Guide
4.2. Permutation feature importance
Permutation feature importance is a model inspection technique that can be used for any fitted estimator when the data is tabular. This is especially useful for non-linear or opaque estimators. The......
Read more at Scikit-learn User Guide
5. Visualizations
Scikit-learn defines a simple API for creating visualizations for machine learning. The key feature of this API is to allow for quick plotting and visual adjustments without recalculation. We provi......
Read more at Scikit-learn User Guide
6.1. Pipelines and composite estimators
Transformers are usually combined with classifiers, regressors or other estimators to build a composite estimator. The most common tool is a Pipeline. Pipeline is often used in combination with Fea......
Read more at Scikit-learn User Guide
6.2. Feature extraction
The sklearn.feature_extraction module can be used to extract features in a format supported by machine learning algorithms from datasets consisting of formats such as text and image. Loading featur......
Read more at Scikit-learn User Guide
6.3. Preprocessing data
The sklearn.preprocessing package provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream esti......
Read more at Scikit-learn User Guide
6.4. Imputation of missing values
For various reasons, many real world datasets contain missing values, often encoded as blanks, NaNs or other placeholders. Such datasets however are incompatible with scikit-learn estimators which ......
Read more at Scikit-learn User Guide
6.5. Unsupervised dimensionality reduction
If your number of features is high, it may be useful to reduce it with an unsupervised step prior to supervised steps. Many of the Unsupervised learning methods implement a transform method that ca......
Read more at Scikit-learn User Guide- «
- ‹