
When I started practicing Data Science, I haven’t thought much about using the Machine Learning model outside of a Jupyter Notebook. My mindset was “the model achieves great classification accuracy so my work here is done”. By mentoring junior Data Scientists, I’ve noticed that this mindset is quite common. In reality, the model in a Jupyter Notebook isn’t of much use to the company. There are a few steps needed to move the model out of a notebook to a real-world environment. This is where many Junior Data Scientists fall short (and not just Juniors!)—so don’t be like them and learn at least the basics of these 5 skills.
Machine Learning is evolving — it is not just about math and statistics anymore
Software Engineering
Compiled languages
When your model needs to make fast real-time predictions you most likely need to reimplement it in a compiled language like Java or Go. Coding in compiled languages can be challenging if you haven’t done it before. You need to know how debugging works — the process of identifying and removing errors from computer hardware or software. Knowing how to use an integrated development environment (IDE) is also a big plus.
You also need to be well versed with object-oriented programming (OOP). In layman terms, OOP refers to the data type of a data structure and functions that can be applied to it. It is a paradigm for designing the software.
In layman terms, OOP refers to the data type of a data structure and functions that can be applied to it.
Design patterns
How to structure the code so that it will stand the test of time? Design patterns (DP) might have an answer to that question. DPs describe good practices of how to properly structure code to commonly occurring problems in software design. Object-oriented programming mentioned above is one of those design patterns. While studying DP you will get to know Facade, Memento, Visitor and other fellow patters with intuitive names.
How to structure the code so that it will stand the test of time? Design patterns!
Testing

Automated Software Testing is also an area that is commonly overlooked by junior Data Scientists. “I don’t have time to write a test” and “It works on my machine” are phrases that you might hear from them. When working on a project that will run in production, tests are a must. May that be a unit, mock or integration test — any kind of test is better than no test.
So what are those unit, mock and integration tests?
- A unit test tests an output of a function with certain input parameters.
- Mocking uses mock objects that mimic the behavior of real objects in controlled ways.
- Integration testing means that you run your code as it would run in production. It tests interactions between different components.
May that be a unit, mock or integration tests — any kind test is better than no test
Cloud Computing

Instances
When developing a Machine Learning model, your laptop might not have enough horsepower to train the model. Cloud providers, like Amazon, Google and Microsoft, offer instances with GPUs that are far more powerful than the GPU in your laptop. You spin the instance, train the model and turn the instance off — you pay per hour so don’t forget to turn it off 🙂.
Services
Cloud providers also offer infrastructure to process large quantities of data. Like distributed disk storage in the cloud (Amazon S3, Google Cloud Storage), which is the main building block of data lakes. Reporting and analytics in tech companies are usually supported by distributed databases that can process big data (Amazon Redshift, Google BigQuery). Those databases store data tables by columns, which is different from typical relational databases like Postgres.
Microservices
The awesome model that you’ve built has to live somewhere and that is not on your laptop. Microservices (Machine Learning is not the only buzz word) are becoming a more and more popular way to put ML models in production. Usually, the ML model runs in a docker container and it can be separately updated without impacting other parts of the application. If it fails, only a small component of the application fails. Need faster predictions? Simply scale the microservice with the ML model.
Need faster predictions? Simply scale the microservice with the Machine Learning model.
Command Line Interface
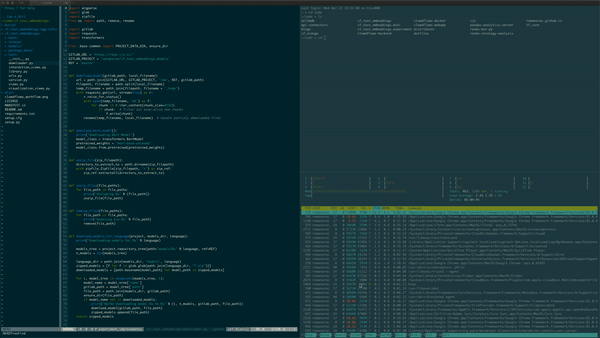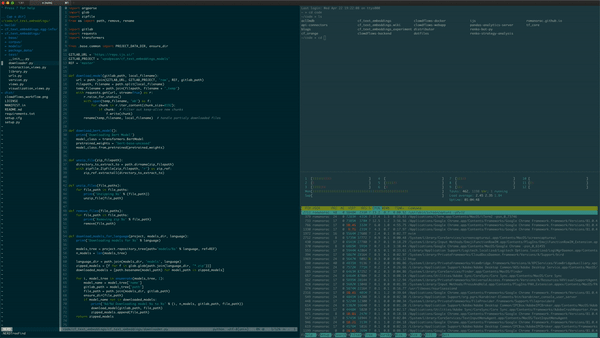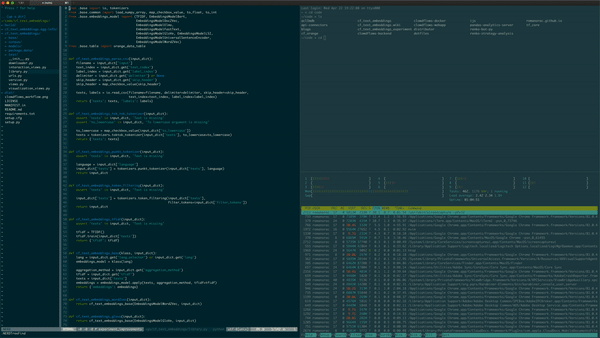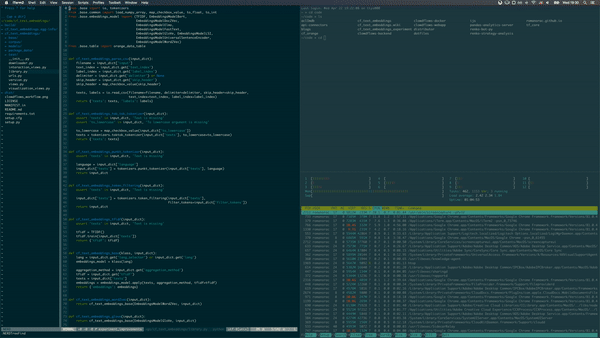
Command Line Interface (CLI) or BASH on a Linux machine. Ever wondered what BASH stands for? Bourne Again SHell.
Why is it important to have a basic knowledge of CLI? By using an instance hosted by a cloud provider, you sometimes need to connect to it, transfer files, run a script when you disconnect or install a missing dependency — using CLI.
You can even edit code in CLI by using Vim or Emacs. By spending some time you can configure Vim to work like an IDE. I use manly Vim for development so when coding I only use two apps: iTerm and Chrome. I asked a colleague, why should I learn Vim? He replied: it is installed on most Linux machines and it won’t ever change — learn it once, use it forever.
The CLI commands I use often are:
- head to see the first few lines of a file,
- ack to search in files,
- jump to jump to a directory,
- htop to list the processes,
- ssh to connect to a remote machine,
- tmux to keep running script when I disconnect from a remote machine,
- neovim to edit files.
CLI is here to stay. Learn the basic commands
Git

Git is version control for code. The concept of git is simple, but it has a learning curve. I hated it at first but then we became friends along the way. The easiest way to learn it is by practicing it. GitHub is a great place to start as it offers free public and private repositories. Public repositories are great for your resume. You can even host a blog on GitHub — I’ve used it before starting publishing on Medium.
Knowing the basic commands of git is a must for anyone who writes code: clone, add, commit, push, merge.
Remember, newer push passwords to a git repository. What goes to git, stays on git.