
Do not Stick to a Single Method
You may have heard this: “no free lunch”. This is actually the name of a theorem. A theorem that basically says “no single method works best for all machine learning problems” (you can read more about the theorem here). No matter how complicated or simple a method is, it will not perform best for all the problems. For you as a data scientist, this means that if you want a good performing model, you need to explore different methods. Sorry, deep learning may not perform the best for that problem you are working on…
There is no free lunch because every method makes assumptions about the problem. One example for assumptions: if two instances are close in feature space, they must be similar (i.e. smoothness). Another can be that linear methods assume that the data is linearly separable (e.g. logistic regression, linear SVM). In addition to that, methods’ assumptions and their robustness against them vary. For instance, the nearest neighbor classifier makes a very strong assumption on smoothness. This means if you have a very good distance metric, you can achieve great results with it.
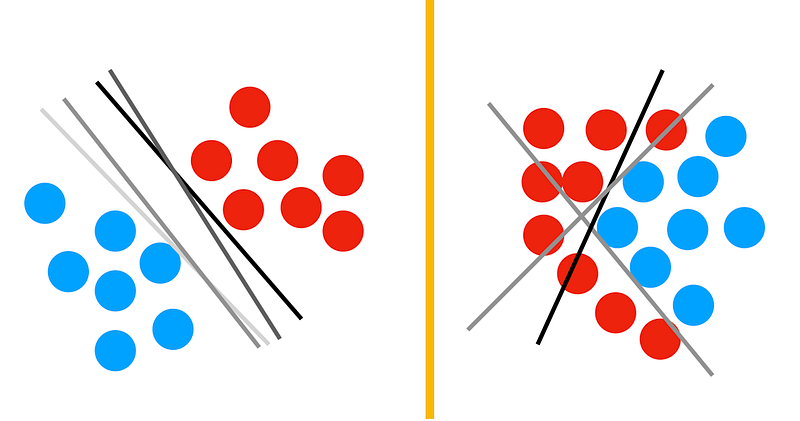
Given all these, it is a good idea to explore different methods rather than sticking with one. But which one to start with and which one to try next?
Start Simple
Agile methodologies suggest that we should develop with iterations. Meaning that we should not try to solve everything at our first attempt. For data science, this means that we start with a simple approach, and gear up as we go. The first iteration should have a simple version of every step (e.g. processing, feature extraction), thus it should have a simple method.
In early iterations, it is better to pick a simple method. A simple method that is easy to implement, understand, and debug. Also, it should not require intensive computations or expensive hyper-parameter searches. When you work with a simple method, it is easier to catch errors, bugs, and fix them. A simple model may perform poorly, but you will have that model very quickly.
An instance of a simple method can be the nearest neighbor. It takes a few lines of code to implement, and its approach is very straightforward*. You can even consider not using a machine learning method. Sometimes I go with a random predictor or a very simple if clause in my first iteration. These simple approaches pose baselines for your problem. Although I call them simple, there is no reason why simpler methods cannot be superior to complex ones. Sometimes simple methods can yield interesting or good performances.
Gear Up
After your first iteration, you will have a model and a baseline performance. Now you can continue iterating. In each iteration, you gear up and try a different approach. As you iterate, I suggest that you take a small step at a time. In each iteration, you improve one thing. This will allow you to compare how your changes affect the performance and monitor your improvement over time. It is also easier this way to find if there exists a problematic operation as your performance will drop in that case.
Performance vs. Expectation
You always derive for better performances. However, maybe the one you already have is enough. As you keep working on your problem, getting improvements becomes harder. Small improvements start to take longer and become more costly. For instance, if you have 99% accuracy on your problem, maybe you should not spend more time and resources pushing it to 99.2%. Depending on your problem and the expectations, you may have reached a point that your model is performing sufficiently.
For instance, if you investigate digit recognition using MNIST dataset, you can find that a K-nearest neighbor without any preprocessing reaches to ~3% error rate. This means that with a simple model, you can recognize 97 digits out of 100 correctly. If that performance is good enough in your case, you may stop working on trying to get a better model and deploy your solution. In the end, you spent little time to deploy a solution without wasting your resources on complex methods. This approach is easier to perform with iterative development rather than starting with a complex method and sticking to it.

* One can argue that the nearest neighbor is computationally expensive as it calculates a distance matrix between test instance and training dataset. That is the case if the number of features and training dataset is large. Like in any case, the practitioner should investigate the method and the data.