
An amazing idea pops into your head: You can use machine learning to build an application and provide enormous value for society. Maybe you can create a company from this idea.
Everyone will love it.
Wait.
Machine Learning needs data.
You’ve had the idea. You’ve validated it. It sounds great. But…how are you going to get this data?
The first step towards building a machine learning application is deliberating what kind of data we might need and searching in the relevant application domain.
If we try to predict shoe size using an individual’s eye color, the application will probably not work very well. Predicting who will win presidential elections using meteorological data is likely not a good idea.
We have to use the right kind of data.
Once we have discovered the type of data that we want, we have to find or gather this data, which usually, if we don’t have any pre-built data-sets, derives in another problem: where to get the data from and how to label it.
In this post, we will describe techniques for gathering data for specific applications, and also we will discuss how to label data that we have previously collected. It will be divided into the following parts:
- Data Labelling: An introduction — What data labelling is and why we need it
- Best practices for data labelling — Tips and tricks for how to label data
- How individuals and teams label data — Current ways to find labels for your data
- Data labelling tools — An overview of the best tools in the market for data labelling
If you feel you will like this, sit back, relax, and enjoy!
1) Data Labelling: An introduction
With all the hype around AI, many times organizations want to use it to solve problems that don’t necessarily need such a sophisticated solution. The aim to build an Artificial Intelligence or Machine Learning system has to start with a clearly defined goal in mind that can be most optimally solved using these techniques.
If we decide to use a machine learning based solution, its results (the predictions) have to be evaluated in order to see if they have enough quality or if they are biased in any way.
This leads to a highly iterative process that consists of the initial model training as well as the periodical re-trainings once models are put in production.
Real world scenarios rarely involve perfect data like the one we could get in Kaggle competitions or data sets from online courses. Most time data is messy, incomplete, disorganized, and many time lacks quality labels.
Data labelling is the task of taking a data set that comes with no data labels and somehow incorporating those labels. An example of this could be downloading thousands of images of cats and dogs and manually saying ‘this one is a cat’ or ‘this one is a dog’ and registering it.
It is a task that is mostly needed when we are working on a very defined problem for which we are building a specific solution.
For example, for a Twitter Sentiment analysis project, I manually labelled (with the help of some friends and in exchange for some cold beers) about 10000 tweets, assessing if they had a positive, negative, or neutral tone.
For another project, I had to label manually about 1500 images of high voltage towers to see if they had any sort of problem or were rusted.
By labelling this data we prepare it so that our data-hungry supervised machine learning models can learn from it.
These models will learn from what they see, being the labels of the data a critical part of what will make our models work well or fail terribly.
Being completely honest, data labelling most times is a boring and tedious task. Nobody wants to do it. But sometimes, you just have to, so you might as well do it properly. Want to learn how? Then keep on reading.
2) Best practices for labelling data

If you ever face the task of having to manually label data, there are some best practices which you ought to know in order to get the best possible results:
- If you can, always use a tool that has been designed for data labelling (we will see the best tools out there later)
- Data labelling is a repetitive task, so whatever tool you use it ought to be simple and intuitive
- People can make mistakes, so always have someone rechecking the labelling if you can
- There has to be an audit to asses if the data has been correctly labelled
- If you have the expertise, consider automated data labelling or semi-supervised learning: machine learning to the rescue of machine learning
Once a Machine learning model has been trained, it can be of huge help to further labelling new data.
We probably shouldn’t let the model label all of the data, but rather, we could use it to assist our teams in the data labelling, using the model to give them insights and even automatically allowing it to label data points for which it has high confidence.
Awesome, so now we know some best practices, how do we actually get down to it and label our data sets? Let's see it!
3) How individuals and teams label data
There are various ways for labelling data that are harnessed by individuals and organizations in order to complete this highly tedious and manual task:
- Manually labelling the data themselves (boring and time consuming)
- Hiring remote teams in countries where labour is inexpensive or dedicated organizations
- Hiring individual freelancers to manually label this data or try to come up with a clever solution like web scrapping the labels
- Crowdsourcing: using platforms like Amazon Mechanical Turk or Figure8.
Depending on your economic and time budgets some choices might be more suitable for you than others, but there are various things you should take into account regarding the previous best practices if you are outsourcing the labelling.
If you are hiring remote teams or asking another business to label your data, make sure you define very precisely how to do this, and ask for a sample of labelled data right at the start in order to double-check that it is being done correctly.
For freelancers with clever/automatic labelling techniques do the same but with even more emphasis on auditing the quality and correctness of the labels. Make sure also to understand the process they are following.
Platforms like AMT and Figure 8 come with some automation for this process: many data points get labelled by two or more annotators in order to assure that the labels are homogeneous, and you get a nice online interface to accept or reject any labels that you double-check.
How to get labelled data
If you don’t want to go through a manual labelling process, there are a couple of things you can do to collect data that is already labelled:
- Surveys: you can create online surveys where by answering the questions the users will be labelling your data.
- Noisy Labeling: noisy labelling consists on automatically labelling data following a set of rules. For example, if you wanted to label tweets according to their sentiment (positive or negative) you could collect tweets with a smiley (😊) face and an angry face (😠) and label those with the smiley as positive and with the angry face as negative.
- Kaggle and pre-made data sets: Kaggle, the famous Data Science competitions site also has a data set category where you might be able to find data that suits your needs. Also, there are a lot of data set repositories online.
- Data Mining: If you have to build an ad-hoc data set you can use an indirect data mining technique to gather the data. For example, I worked on a project once where we wanted an intelligence shoe size recommender for different brands and even shoe models. Sometimes a 42EU Nike size fits different than a 42EU Adidas. We wanted to take individual's feet measurements and build a model that would recommend a size for a specific brand. For some brands, we scrapped the typical size sheets from their websites. For others, we hired a freelance to gather the equivalences. Lastly, to gather more data and fact check the one we already had we built a landing page that recommended users their shoe size for a specific brand using their feet measurements using very simple rules, but only if they gave us their size for another brand. By doing this we gathered even more data.
Let's finish by seeing an extensive overview of the data labelling tools on the market, their pros and cons!
4) Data labelling tools
If the situation comes where you have to manually label a data set, there are many tools in the market that you can use. How do we choose one?
The tool that you choose has to be adequate for the specific labelling task that you are facing: there are some tools to label images efficiently, others that are built specifically for labelling texts, and so on. The first thing, therefore, is identifying your labelling needs and choosing a tool that satisfies them.
After this, if you have a budget, you will have to choose between a paid or a free tool. While paid tools are usually better there are some great free tools out there, which we will see in a minute.
Most of these tools are simple and agile, as they are built with a specific purpose in mind (assisting people in labelling data), however, they all have their individual differences and some of them are more user-friendly than others.
Let's check them out!
LabelImg
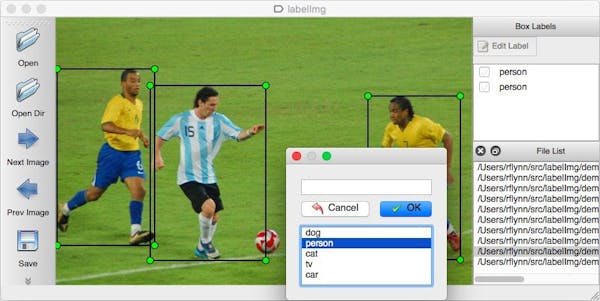
We will start with an image annotation tool used for object detection and segmentation. For an image classification task (identifying if an image corresponds to a dog or a cat for example) we don’t normally use a standard tool, as we just need to register the class in the convenient format.
LabelImg is a graphical image annotation tool written in Python. It provides a really simple interface to navigate through a folder of images and allows users to create bounding boxes around specific objects within the images.
The annotations are saved as XML files and can be easily transformed into a format that will be understandable by most computer vision models like Yolov5. In the following image, you can see a snapshot of the interface.
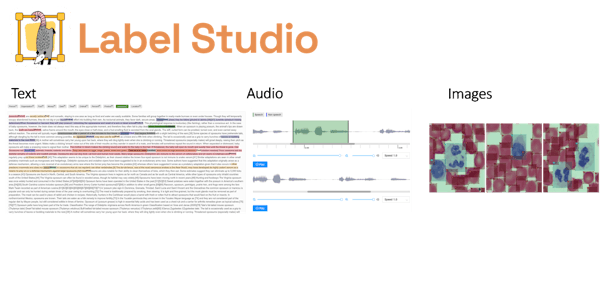
Label Studio
Label Studio is an open-source labelling tool that suits any kind of data labelling task: it can do images, text, audio, time series, and even multi-domain labelling.
It is probably the most complete data labelling tool in the market and the one that we would recommend to master if you are going to be labelling data regularly.
SuperAnnotate

SuperAnnotate is a data labelling SaaS that also has an SDK that allows it to integrate with any application. Like Label Studio is a multi-task labelling tool that supports images, videos, and text labelling, as well as other tasks like data curation, automation, and quality management.
It also has an annotation marketplace similar to what you could find on a service like Amazon Mechanical Turk (AMT) or Figure 8. It is a paid tool, so we only recommend it if you are part of a company that regularly has to label data for its operations.
Clarifai

Clarifai is a tool that is very similar to Super Annotate, and also has an API integration. With Clarifai you can label images, text, video, with two different kinds of paid offerings, but you can also do much more.
It also has a no-code prediction platform which you can integrate with the labelling services and various out of the box tools like software to detect possible failures in machines for predictive maintenance.
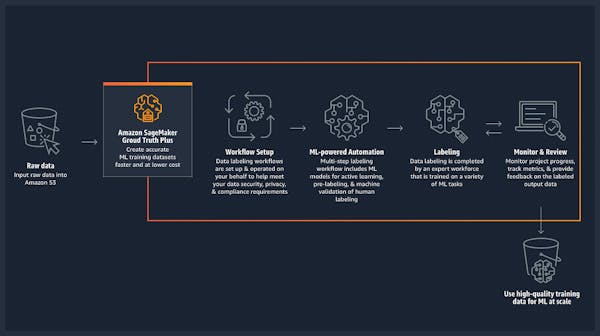
Amazon Sagemaker

Amazon Sagemaker, the data / AI platform of Amazon Web Services has two different data labelling frameworks: Amazon SageMaker Ground truth and Ground Truth plus.
The plain vanilla Ground Truth is a data labelling service that also gives the chance to use human annotators through Amazon Mechanical Turk or other similar providers.
Ground truth plus incorporates all kinds of intelligence into the standard labelling tools like shown in the following figure:
Prodigy

Prodigy is a paid data labelling tool created by the makers of Spacy, the famous Python NLP library. It is powered by active learning and state-of-the-art insights from machine learning and user experience.
The web interface is very easy to use, and the recommended labels by their tool are highly accurate and only prompt when needed. It is one of the best tools for annotation in the market, however, it does come at a very high price point.
The Snorkel library

Snorkel is a really innovative concept: a way to create a series of ‘messy’ labelling functions and combining them in an intelligent way to build labels for a data set.
It was initially developed in 2016 by Stanford University, it is widely deployed in the industry, and has been the subject of many research papers in top congresses and publications.
In a nutshell, what Snorkel does is programmatically build and manage training datasets. This means that the library provides many pre-defined functions for labelling data that you can use right away. You can also customise these functions to extend or change their functionality.
There are other tools like Appen or Google’s Cloud Platform data labelling services, but for me the ones highlighted above are the ones you should have on the top of your mind when you need to get some data labelled efficiently.
Conclusion
In this article, we have seen what Data labelling is, explored some best practices and tips and tricks, and seen a quick overview of the main tools in the market.
I suggest that you try out a couple of them, even for a dummy or made up task in order to get yourself familiar and see what they are capable of in more detail.
For more advice and posts like this follow me on Twitter, and to find reviews of awesome data science books, check out the following repository.
Have a wonderful day and enjoy AI!