
When I tell people that I work as a Data Scientist, I get asked the same questions many times:
How did you end up doing what you do? How did you learn? Did they teach you this at university?
I studied Industrial Engineering, which has very little to do with Data Science or Machine Learning, although it does have a little programming in C on its curriculum.
When I tell people what I studied, and then what I do for a living, the first of these questions appears: ‘How did you end up doing what yo do?’
I’ve always been passionate about computers and software, and I ended up doing Industrial engineering because it is a very general engineering degree, and because I also liked physics, thermodynamics, electronics, and the energetic industry, I decided to take a general bachelor, discover what I loved most, and then go for it.
This means that during the 4 year bachelor I studied, I didn’t get many useful knowledge that would later serve me in my professional life, although I did pick up some low level C programming, which served as an introduction to software development and programming, and allowed me to see that it was this area where I wanted to focus my future efforts.
With this in mind, as soon as I discovered that something related to programming was going to be what I wanted to do in my first step into the laboral world, I started taking courses by myself: first I kept learning C and incorporated object oriented programming into my toolbox by learning C++.
After that I learned some web design with HTML, CSS, PHP, and JS, and all the theory behind communications in networks and TCP/IP. I did this through a mix of university courses, YouTube videos, and internships.
To continue expanding my programming expertise, I started to learn Python on Udemy, and quickly added SQL and NoSQL to my knowledge using this same platform.
Lastly, I did the second year of my master’s degree in Industrial engineering taking mostly Computer Science courses: Operating Systems, Cybersecurity, UX, and Machine Learning and Data Science courses. It was at this time that I decided to focus on Machine Learning, and ended up doing a wonderful Master Thesis about Social Network Analysis using NLP, while doing 3 or 4 Udemy courses on Machine Learning and Data Science at the same time to complement this project-based learning.
This was the last step of my academic life, and after it I had to start to search for a job in the field of Data Science. I still had a lot to learn, so I bought some books, like ‘Hands-on Machine Learning with Scikit-Learn, Tensorflow and Keras’ or ‘Python Machine Learning’, and devoured them while I was preparing interviews.
This was my path towards getting a job in the field of Data Science. If I had to do it again, knowing that this field was going to be where I ended up, I would change many things.
The goal of this post is to highlight what knowledge I think is most important in the Data Science and Machine Learning industry, and how I would obtain that knowledge if I had to start from scratch.
I will speak about specific areas of knowledge where I would have spent more energy and time, as I think that they are very important in the day to day life of a profesional Data Scientist, and that if learned correctly can surely lead you to becoming a great expert.
Get ready, and I hope you like it.
Lets go!
1) Study Computer Science or Software Engineering from the start

If I had known when I was 17 years old that 6 years later my passion was going to be Data Science, I would have gone straight away into a Computer Science bachelor.
In the end, Data Scientists, Machine Learning engineers, and so on, code programs that are going to be used in some sort of application. This means that the better they are at professional software development, they better and more confortable they are going to feel at their jobs.
There are people that are analytical geniuses but lack very basic software development methodologies, which makes them a lot less efficient and proficient at their job than they could be.
Knowing and implementing the best possible software development practices and being comfortable with coding, looking up documentation, and so on, is something that can take a Data Scientist from good to great, and I think that a bachelor or a degree in Computer Science gives its student just that.
People with this background spend so much time around code and software that it is kind of second nature to them and they feel extremely comfortable in any kind of situation that revolves around it. Therefore, they are usually very efficient coders and can build and design great applications.
Knowing the architecture of the internet, different communication protocols, how to use APIs, when to use different databases, the SOLID principles, and all the knowledge that is picked up in a Computer Science degree is of great help in the professional life of any Data Scientist, so if I had to start from scratch and rethink my academic life, I would definitely study Computer Science.
In conclusion, even if it was not through this path, the things I would try to understand and get really good at would be:
- Git and Version control: Fundamental for building a portfolio and working in teams. Understanding Git, Code repositories and Version control is something fundamental for every Data Scientist.
- SOLID Principles and Object Oriented Programming: Data Science and Machine Learning can and should be differentiated in two different pipelines: Training and development and productization and deployment. While the training, and analytical part is something that is more ‘craft’ oriented, and should be done manually, mostly in interactive environments like Jupyter Notebooks, the deployment phase is something more intrinsically related to software development, and should be surrounded by all the associated best practices of Continuous Integration and Deployment, Testing, POO, and so on.
- Programming in multiple languages: Having expertise in a couple of modern programming languages like C or C++, or Go, or Julia, aside from the most popular Python, R or Scala, is something that will give you a great deal of flexibility when tackling Data Science and Machine Learning projects.
- Knowledge of network architecture and protocols: Nowadays most Machine Learning and Data Science projects are carried out in the cloud. Services from providers like Amazon Web Services, Azure, or Google are widely used when training and deploying Machine Learning models. Having a good understanding how network protocols like SSH, TCP/IP, FTP, and so on work, as well as the basic Client/Server architecture, is key for being able to work efficiently in these environments.
- How an Operating system works and some hardware understanding: Memory management, Multi-threading, Hardware abstractions and pretty much how our PCs manage everything we do. The hardware architecture of modern computers, what CPU, RAM, GPU and so on do, is very important when deciding how many resources to allocate to a certain project. This knowledge will also be of great use when using softwares like Spark and so on, and clusters of nodes to train Machine Learning models that harness a lot of data.
- Databases and their associated languages: Most industrial Data Science projects revolve around some kind of tabular data, that on its origin is located in some sort of SQL Database. The use of services like Google’s Big Query is widely spread, and the first step in many of these projects is extracting exactly the data that you need from these original infrastructures into the analytical environment where the data will be analysed and the models will be built. Also, NoSQL databases are becoming more and more frequent with the rise of mobile applications and the tsunami of unstructured data like text and images.
You don’t have to know all these topics in depth, but being comfortable in conversations around them, and knowing about how they are all useful will make your life as a Data Scientist much simpler.
2) Enjoy and engage with Statistics Courses

During my university path, I had various statistics, probability, and statistical test design courses. All the knowledge that I could have obtained from them would have turned out to be extremely useful in my posterior professional life.
However, as most university students, I passed through these courses studying what I needed to succeed in the exams, and not thinking about the practical applications of what I was learning. I would later regret this deeply, as when I started learning Machine Learning and Data Science it turned out probability was embedded everywhere.
Not only are statistics and probability a fundamental part of modern Data Science that you need to understand, but having a profound knowledge of some of its most undervalued parts (Chi-squared, T-tests, F-distribution…) will definitely take you a step higher as a Data Scientist and differentiate you from the rest of your colleagues.
Many concepts surrounding Machine Learning requiere some sort of statistical knowledge to correctly grasp. Some of them are:
- Explained variance in PCA: When doing Principal Component analysis each of the principal components explains a percentage of the variance of our data. The more explained variance, the less information we loose, but the more principal components we need.
- P-values and alpha thresholds in outlier detection and feature selection algorithms like Boruta. Knowing what p-values mean and how to set the alpha value in each case can lead to very different results in these kind of experiments.
- Checking for degradation in Machine Learning models that are put in production using standard machine learning metrics like AUC, and also other kind of statistical tests.
- Understanding percentiles and cuantiles for creating thresholds for segmentation and data characterisations.
Because of all of this, I wish I had paid a closer attention to my statistics courses at university, but as I couldn’t go back in time, there are fabulous resources that can be used to grant you this same knowledge if you have not had the luck to have any statistics or probability course, or if as I did, you flew pass it without paying much attention.
I will list some here for you:
- ‘Bayesian Statistics the fun way’. A great little book that gives a fun and theoretical approach to Bayesian Probability.
- ‘Practical Statistics for Data Scientist’. A very practical book that covers the topic of statistics oriented specifically towards data scientists and Machine Learning engineers using Python and R.
- There are many great statistics and probability courses out there. I have listed a bunch of them on the following link. Some of them are free and some are payed, but all of them are definitely worth the time, and will be of great use to your Data Science career.
At the end of the article you can find a link with detailed reviews of both books.
In conclusion, the better you understand statistical concepts, the better Data Scientist you will be. If you are still at that point in time where you can take courses at university, do yourself a favour, pay close attention to them, engage, and enjoy; probability and statistics is not only useful, but once you get the hang of it, it is extremely fun and interesting.
If you are passed that point, then check out of the previous resources, but make sure you start learning about these topics as soon as you can. The main things you will need to grasp are:
- The main statistical concepts of mean, standard deviation, percentiles, and confidence intervals
- What p-values are, what they are used for, and how to calculate them.
- The main probability distributions: Gaussian, Binomial, and the Beta Distribution.
- Statistical tests such as T-test and Chi-squared test.
- Other tools like Schniders Distribution, Poisson, and Bayesian probability.
With all of this in your toolbox, you will be the king of Data Science, and if you have already learned all the Computer Science fundamentals of part 1) you will be on your path to becoming a great professional.
Lets see what else you need!
3) Don’t forget the maths: pay close attention to Calculus and Algebra, and pick up the fundamentals
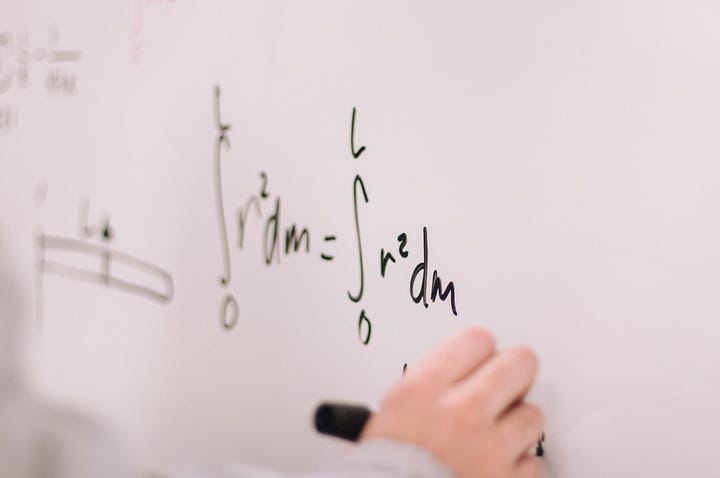
Mathematics is one of the basic building blocks of every discipline that conforms Data Science: Statistics and Probability, Computer Science, Machine Learning, Deep Learning… all of them use some sort of math, and you should have a level high enough to understand the fundamental mathematical components of each branch.
For example, although you can go by and still be a performing Data Scientist without much algebra and calculus knowledge, I would say understanding the fundamentals is essential, and going a little bit further and not only understanding but having a perfect grasp and intuition behind the following concepts is of great use:
- Derivatives and Integrals. Derivatives are used in procedures like gradient descent, and integrals are used when calculating probabilities and in other areas, so understanding what they mean is very useful.
- Linear algebra: Knowing what vectors and matrices are. The concepts of the inverse of a matrix, vector spaces, and vector matrix multiplication is and so on, can help you understand how many algorithms like Linear Regression and Support Vector Machines work under the hood.
As we mentioned earlier, statistics and probability knowledge is something that can differentiate a decent Data Scientist from a great one, and mathematical capabilities are embedded at the core of probability and statistics.
Computer Science, and digital electronics, which build up to the precious laptops, PCs, servers, and architectures where Data Science happens, are built on top of Boolean logic, a very fun and useful branch of mathematics.
Knowing what vector-matrix multiplications mean, and the intuition behind linear algebra will let you know, when operating with matrices and vectors in your data manipulation phase, or when implementing algorithms from scratch, exactly what you are doing in each step.
A great resource to learn all this are 3Blue1Brown’s videos on Youtube. They are absolutly wonderful.
4) Lean and understand the guts of the different algorithms

If you have taken all the previous steps, covered in 1), 2) and 3), gathering all the knowledge from these respective areas, and consolidating it in your head, you will have an outstanding foundation to go into Machine Learning and Data Science.
As a starting point, many people take courses that involve some sort of programming using frameworks like Scikit-Learn, and that only cover the theory behind algorithms like Linear and Logistic Regression, Decision Trees, Random Forest, Support Vector Machines, etc… very superficially.
While this is a good step to see what is out there, I deeply encourage you to follow it through with a textbook of some sort, or any other kind of formation that dives deep into the guts of how the algorithms work.
Things like understanding the process of gradient descent, how a decision tree is built, the different boosting methods and their advantages, how unsupervised algorithms like K-means find groups in our data, and how neural networks work, and their different architectures are very useful.
Why? Even if libraries like Keras or Scikit-Learn hide the guts of each algorithm, and allow you to simply do .fit() to train them, all of the classes that implement the models in these frameworks have a lot of parameters, which can lead to very precise customisations of each of the algorithms.
Understanding what happens deep down in each of the algorithms will allow you to cleverly select these parameters, know what they mean, and optimise the training procedures to obtain the best possible results.
My advice is: don’t stay just on the most superficial layer of how things work; dive deep down and get a profound understanding, which will allow you to perform both, low level and high level tasks much better.
Aside from some of the textbooks I have previously mentioned, you can get fantastic, in-depth explanations of each of the Machine Learning algorithms with StatQuest’s Youtube channel. Check it out! If you prefer an online written format, Machine Learning’s Mastery guide to the different algorithms is also great.
5) Self learn as much as you can

As with most technological fields, Data Science and Machine learning are very dynamic, with new tools, frameworks, and algorithms being developed continuously.
Because of this, it is very important that you keep updating your knowledge to stay up to date with the field, and prevent it from becoming obsolete.
Also, if you are starting out, maybe with some Computer Science or Mathematics bachelor, it is a good idea to start taking your first baby steps towards Data Science and Machine Learning, either in the form of some introductory book or some kind of entry level online course.
Once you are already in the field, there are many ways to keep up with what is happening: subscribe to newsletters, listen to podcasts, read the newest papers, and follow the conventions and congresses that happen during the year.
Also, play devils advocate, and when you read some AI related article on the regular press (which tend to very superficially explain what the actual AI does), dig deeper, investigate, do your research, and find out what it really is about.
Read blogs like this one or Medium, where you will find interesting articles every day, some of which will most definitely catch your attention. Follow big personalities on the field of Machine Learning like Andrew Ng, Yann Lecun, Sebastian Raschka, Pedro Domingos, or Andrew Task on Twitter, and engage with their content.
Lastly, try coding a little bit when the most popular frameworks or languages suffer minor updates to see what is new.
As you see, there are a lot of ways to keep learning, and in a field where this continuous development is so important, the best tip I can give you is to let your curiosity and your love for what yo do guide you.
6) Build projects and make a portfolio

I’m a big believer in learning by doing. Step number 6) is the time to take all the theoretical and practical knowledge you have gathered and make it real.
The time to build something.
This will not only allow you to become more familiar with the different tools you have learned to use, but it will also make you build a series of projects that will be of great use when doing interviews and recruiting processes. Interviewers always ask you to tell them about a project that you have done, and having a wide range of them to choose from is great.
Choose projects that are personal, and that arise from your natural curiosity to explore. These kind of projects will be the ones you will most likely be passionate about, they will be fun and engaging and won’t feel like work. Also, when you speak about them, people will see the light in your eyes while you explain what you did.
Try to do projects from different areas of Data Science to gain at least some experience in all of them:
- Do some Exploratory Data Analysis (EDAR), where what you are looking for is to extract some valuable information out of existing data. Present your results in an intuitive and visually aesthetic format.
- Do both, a challenging regression problem with some advanced analytical side (for example using a Geographically Weighted Regression to build a house price prediction model), and a hard classification task, where you show that you know what metrics to consider and optimise.
- If you feel comfortable, try to do a Natural Language Processing project. With so many APIs out there from Social Media applications, there is a lot of room to build cool projects, specially with Twitter’s fantastic API.
- Try a Computer Vision project, such as an image classification or an object detection task. There are a lot of frameworks and pre-built libraries that can facilitate your job a lot, you don’t have to build the CNN from scratch. Check out YOLO and the Darknet repository if you are interested, and build a cool project that you can brag about like a camera that detects your face in real time.
If you do a variety of projects from this list, you will learn like crazy, as most times the most learning comes when you have to actually tackle a real problem, and you encounter milestones along the way.
7) Conclusion, closing words, and further resources
All of the previous tips and advice are oriented for those who want to pursue a career on the field of Data Science or Machine Learning. For people that want to go onto research, I would say emphasise as much as possible on building knowledge from 1), 2) and 3), pursue 4), and maybe leave 5) a little bit on the side.
If you have followed all the advice from the previous points, you should have enough Data Science knowledge to start your career in the field, and also you will know how to keep updating and increasing your knowledge.
I hope the advice found on this article was useful, and I wish I had read something like this a while back, before taking my first steps on the amazing road of Data Science.
For more advice and posts like this follow me on Twitter, and to find reviews of the different books I have spoken about, check out the following repository.
Have a wonderful day and enjoy AI!