Data Science & Developer Roadmaps with Chat & Free Learning Resources
K-Nearest-Neighbour
K-Nearest Neighbors (KNN) is a fundamental supervised machine learning algorithm used for classification and regression tasks. It operates on the principle of identifying the ‘k’ closest data points, or neighbors, in the feature space to make predictions about a new data point. The algorithm is intuitive and easy to understand, as it simply memorizes the training data without any complex modeling. When a new instance is introduced, KNN classifies it based on the majority class among its nearest neighbors or calculates the average for regression tasks. This simplicity makes KNN a popular choice for various applications in data science.

What is the K-Nearest Neighbor?
K-Nearest Neighbor (KNN) is an easy to understand, but essential and broadly applicable supervised machine learning technique. To understand the intuition behind KNN, examine the scatterplot below…
📚 Read more at Towards Data Science🔎 Find similar documents

Get to know your k-Nearest Neighbor
K-nearest neighbors algorithm (k-NN) is a supervised, instance-based, non-parametric algorithm which makes use of the k closest examples in the feature space. Supervised means that it needs to be fed…...
📚 Read more at Analytics Vidhya🔎 Find similar documents

K-Nearest Neighbours explained
K-Nearest Neighbours (KNN here onwards) is an intuitive and easy to understand machine learning algorithm. This post provides a short introduction to KNN. We will first learn how the algorithm works…
📚 Read more at Towards Data Science🔎 Find similar documents
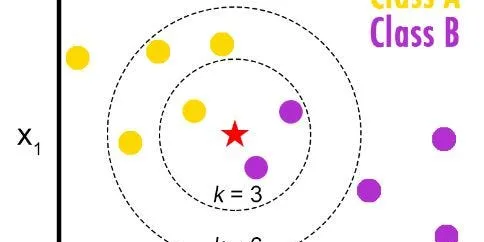
Smarter K-Nearest Neighbours
The K-nearest neighbours (KNN) algorithm is one of the most simple and intuitive machine learning algorithms to understand. If you are trying to classify something into two categories: ‘Yes’ or ‘No’…
📚 Read more at Towards Data Science🔎 Find similar documents

K- Nearest Neighbors(KNN):A Simple Introduction
K Nearest Neighbors is a classification algorithm that operates on a very simple principle. Building the model consists only of storing the training dataset. To make a prediction for a new data…
📚 Read more at Analytics Vidhya🔎 Find similar documents
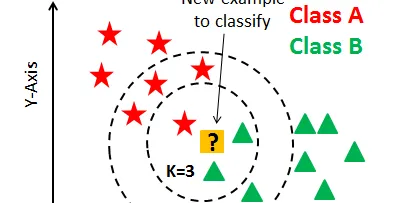
K-nearest Neighbor: The maths behind it, how it works and an example
K-nearest Neighbor (KNN) is a supervised classification algorithm that is based on predicting data by finding the similarities to the underlying data. KNN is most widely used for classification…
📚 Read more at Analytics Vidhya🔎 Find similar documents
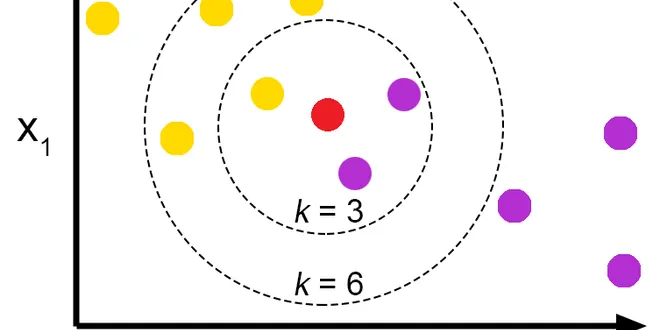
KNN (K-Nearest Neighbors) #1
KNN (K — Nearest Neighbors) is one of many (supervised learning) algorithms used in data mining and machine learning, it’s a classifier algorithm where the learning is based “how similar” is a data…
📚 Read more at Towards Data Science🔎 Find similar documents

k-nearest neighbours
KNN is a simple and intuitive Machine Learning Algorithm. It can be used for both classification and regression. It is a sort of Supervised Learning where we get both x and y. KNN is Non-Parametric…
📚 Read more at Analytics Vidhya🔎 Find similar documents

A Simple Introduction to K-Nearest Neighbors Algorithm
K Nearest Neighbour is a simple algorithm that stores all the available cases and classifies the new data or case based on a similarity measure. It is mostly used to classifies a data point based on…
📚 Read more at Towards Data Science🔎 Find similar documents

How Neighborly is K-Nearest Neighbors to GIS Pros?
Created by the author with DALL E-3 At one point in your life I am sure you have interacted with a nice neighbor, you know, the one who would greet you on your way to work or school, ask how your day ...
📚 Read more at Towards AI🔎 Find similar documents
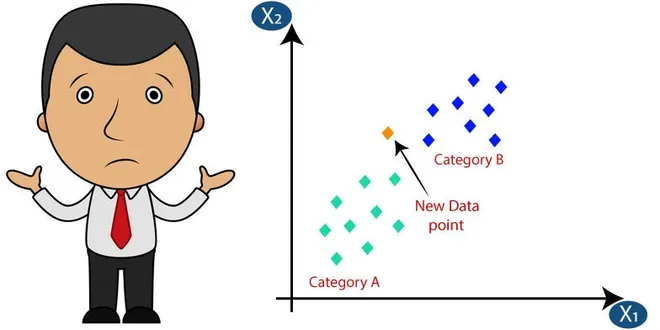
K-Nearest Neighbor(k-NN)
The k-nearest neighbors (K-NN) algorithm is a simple, easy to implement supervised machine learning algorithm. The “K” in k-NN refers to the number of nearest neighbors it will take into…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Everything You Ever Wanted to Know About K-Nearest Neighbors
K-Nearest Neighbors is one of the simplest and easiest to understand machine learning algorithms. It can be used for both classification and regression tasks but is more common in classification, so…
📚 Read more at Towards Data Science🔎 Find similar documents