Data Science & Developer Roadmaps with Chat & Free Learning Resources
It seems you haven’t provided a specific topic or question for the introduction. Please share the topic or question you’d like me to create an introduction for, and I’ll be happy to assist you!

13. External Resources, Videos and Talks
New to Scientific Python?: For those that are still new to the scientific Python ecosystem, we highly recommend the Python Scientific Lecture Notes. This will help you find your footing a bit and w......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents

3.3. Tuning the decision threshold for class prediction
Classification is best divided into two parts: the statistical problem of learning a model to predict, ideally, class probabilities;, the decision problem to take concrete action based on those pro......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents

11.1. Array API support (experimental)
The Array API specification defines a standard API for all array manipulation libraries with a NumPy-like API. Some scikit-learn estimators that primarily rely on NumPy (as opposed to using Cython)......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents

1.1. Linear Models
The following are a set of methods intended for regression in which the target value is expected to be a linear combination of the features. In mathematical notation, if\hat{y} is the predicted val......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents
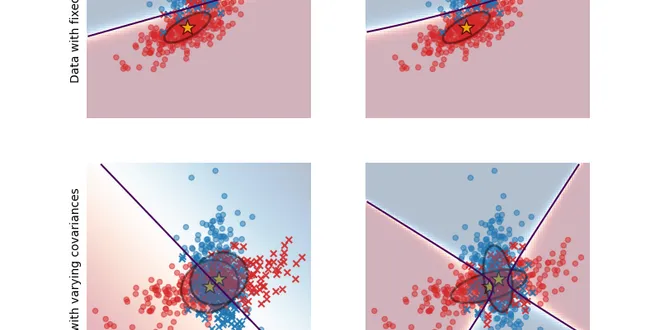
1.2. Linear and Quadratic Discriminant Analysis
Linear Discriminant Analysis ( LinearDiscriminantAnalysis) and Quadratic Discriminant Analysis ( QuadraticDiscriminantAnalysis) are two classic classifiers, with, as their names suggest, a linear a......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents

1.3. Kernel ridge regression
Kernel ridge regression (KRR)[M2012] combines Ridge regression and classification(linear least squares with l2-norm regularization) with the kernel trick. It thus learns a linear function in the sp......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents

2.3. Clustering
Clustering of unlabeled data can be performed with the module sklearn.cluster. Each clustering algorithm comes in two variants: a class, that implements the fit method to learn the clusters on trai......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents
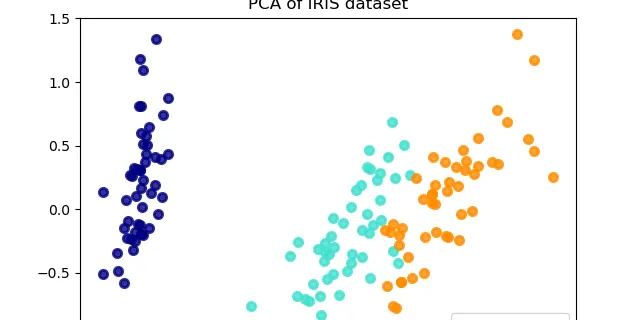
2.5. Decomposing signals in components (matrix factorization problems)
Principal component analysis (PCA): Exact PCA and probabilistic interpretation: PCA is used to decompose a multivariate dataset in a set of successive orthogonal components that explain a maximum a......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents
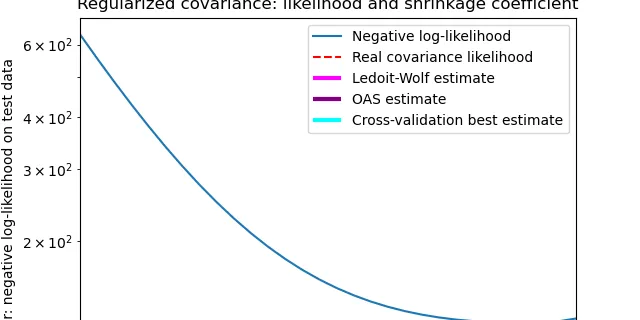
2.6. Covariance estimation
Many statistical problems require the estimation of a population’s covariance matrix, which can be seen as an estimation of data set scatter plot shape. Most of the time, such an estimation has to ......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents
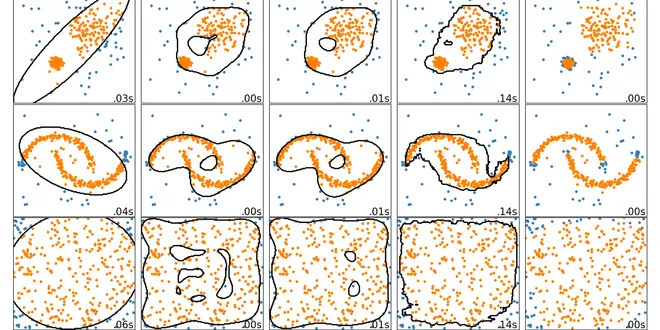
2.7. Novelty and Outlier Detection
Many applications require being able to decide whether a new observation belongs to the same distribution as existing observations (it is an inlier), or should be considered as different (it is an ......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents
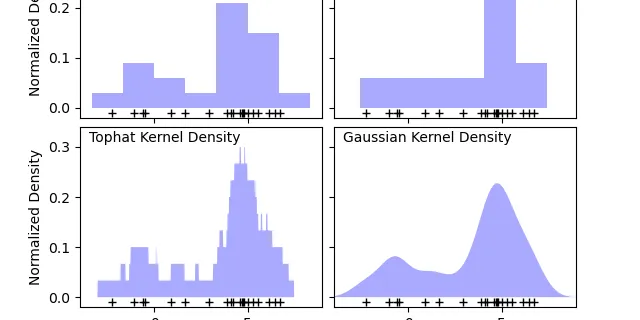
2.8. Density Estimation
Density estimation walks the line between unsupervised learning, feature engineering, and data modeling. Some of the most popular and useful density estimation techniques are mixture models such as......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents
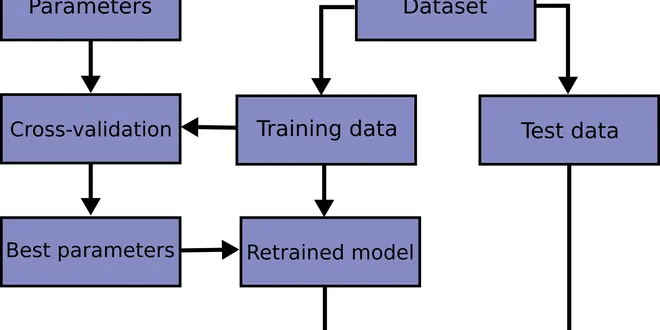
3.1. Cross-validation: evaluating estimator performance
Learning the parameters of a prediction function and testing it on the same data is a methodological mistake: a model that would just repeat the labels of the samples that it has just seen would ha......
📚 Read more at Scikit-learn User Guide🔎 Find similar documents