Apache Flink
Apache Flink is a powerful open-source framework designed for scalable stream and batch data processing. It excels in handling continuous streams of data, enabling real-time analytics and event-driven applications. Flink supports both stateful and stateless computations, making it suitable for a variety of use cases, from real-time data ingestion to complex event processing. With its fault-tolerant architecture and high throughput capabilities, Flink is widely adopted in industries requiring efficient data processing, such as e-commerce and telecommunications. Its flexible APIs allow developers to build robust data pipelines that can seamlessly integrate with various data sources and sinks.
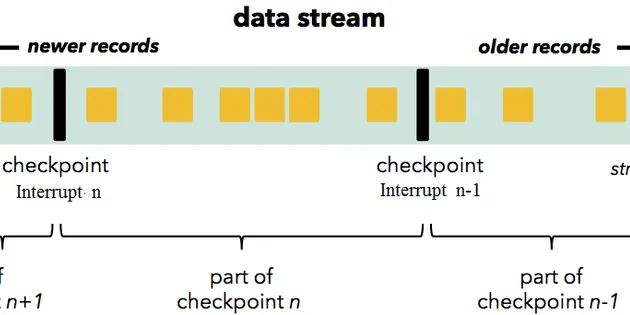
Flink Checkpointing and Recovery
Apache Flink is a popular real-time data processing framework. It’s gaining more and more popularity thanks to its low-latency processing at extremely high throughput in a fault-tolerant manner…
📚 Read more at Towards Data Science🔎 Find similar documents

Apache Flink Series 1 — What is Apache Flink
In this post, I will try to explain what is Apache Flink, what is used for, and features of Apache Flink. Before pass the “use cases for Apache Flink”, let me point to the what does the stateful…
📚 Read more at Analytics Vidhya🔎 Find similar documents
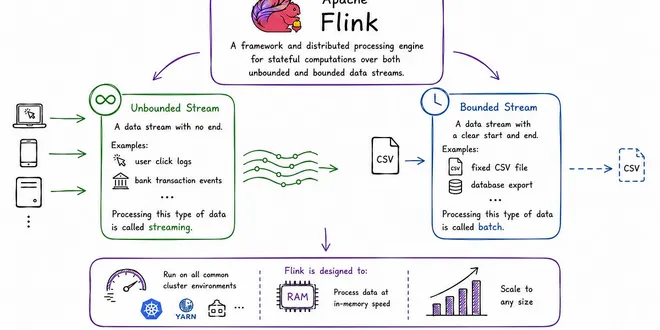
Apache Flink from A to Z: The Engineer’s Guide to Stream Processing
I write practical, deep-dive articles on Data Engineering at https://dinhphuvn.substack.com/. If you found this post helpful, you’ll definitely enjoy what’s waiting for you there. Come join a humble ...
📚 Read more at Level Up Coding🔎 Find similar documents

Apache Flink Series 4 — DataStream API
When we look at the Flink as a software, Flink is built as layered system. And one of the layer is DataStream API which places top of Runtime Layer. close()= is an finalization method. It is called…
📚 Read more at Analytics Vidhya🔎 Find similar documents

An Introduction to Stream Processing with Apache Flink
An Introduction to Stream Processing with Apache Flink
📚 Read more at Towards Data Science🔎 Find similar documents

System Design Series: Apache Flink from 10,000 Feet, and building a Flink-powered Recommendation…
System Design Series: Apache Flink from 10,000 Feet, and building a Flink-powered Recommendation Engine For a while now, I’ve had Apache Flink on my “things I really need to understand properly” list...
📚 Read more at Level Up Coding🔎 Find similar documents

Building a realtime dashboard with Flink: The Backend
With the demand for “realtime” low latency data growing more data scientists will likely have to become familiar with streams. One good place to start is Apache Flink. Flink is a distributed…
📚 Read more at Towards Data Science🔎 Find similar documents

Running Apache Flink with RocksDB on Azure Kubernetes Service
Recently I was looking into how to deploy an Apache Flink cluster that uses RocksDB as the backend state and found a lack of detailed documentation on the subject. I was able to piece together how to…...
📚 Read more at Towards Data Science🔎 Find similar documents

Real-time Twitch chat sentiment analysis with Apache Flink
Real-Time Twitch Chat Sentiment Analysis with Apache Flink Learn how to empower creators by real-time sentiment analysis with Apache Flink to decipher audience emotions to steer content for viewer sa...
📚 Read more at Towards Data Science🔎 Find similar documents
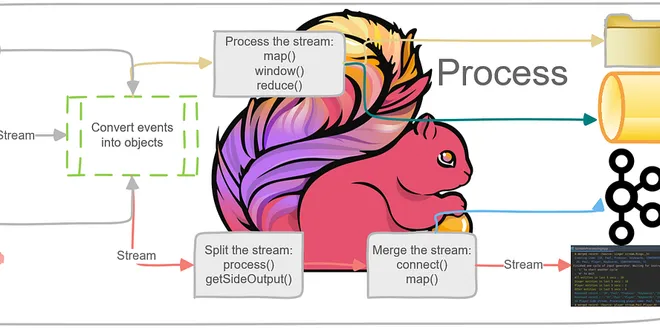
The Foundations for Building an Apache Flink Application
Our monolith solution does not cope with the increased load of incoming data, and thus it has to evolve. This is the time for the next generation of our product. Stream processing is the new data…
📚 Read more at Analytics Vidhya🔎 Find similar documents

How I Dockerized Apache Flink, Kafka, and PostgreSQL for Real-Time Data Streaming
Integrating pyFlink, Kafka, and PostgreSQL using Docker Get your pyFlink applications ready using docker — author generated image using https://www.dall-efree.com/ Why Read This? * Real-World Insight...
📚 Read more at Towards Data Science🔎 Find similar documents

Apache Flume
Trickle-feed unstructured data into HDFS using Apache Flume
📚 Read more at Towards Data Science🔎 Find similar documents