Data Augmentation
Data augmentation is a powerful technique used in machine learning to enhance the size and diversity of training datasets without the need for additional data collection. By applying various transformations to existing data, such as flipping, rotating, or cropping images, models can learn to generalize better and become more robust against overfitting. This approach is particularly beneficial in fields like computer vision, where the availability of labeled data can be limited. Additionally, while image data augmentation is well-researched, techniques for augmenting text data are still evolving, highlighting the ongoing need for innovation in this area.

Data Augmentation
<!--TITLE:Data Augmentation-- Introduction Now that you've learned the fundamentals of convolutional classifiers, you're ready to move on to more advanced topics. In this lesson, you'll learn a trick ...
📚 Read more at Kaggle Learn Courses🔎 Find similar documents

Data Augmentation
<!--TITLE:Data Augmentation-- Introduction Now that you've learned the fundamentals of convolutional classifiers, you're ready to move on to more advanced topics. In this lesson, you'll learn a trick ...
📚 Read more at Kaggle Learn Courses🔎 Find similar documents

Data Augmentation
<!--TITLE:Data Augmentation-- Introduction Now that you've learned the fundamentals of convolutional classifiers, you're ready to move on to more advanced topics. In this lesson, you'll learn a trick ...
📚 Read more at Kaggle Learn Courses🔎 Find similar documents

Text Data Augmentation
Data Augmentation is the process that enables us to increase the size of the training data without actually collecting the data. But why do we need more data? The answer is simple — the more data we…
📚 Read more at Towards Data Science🔎 Find similar documents
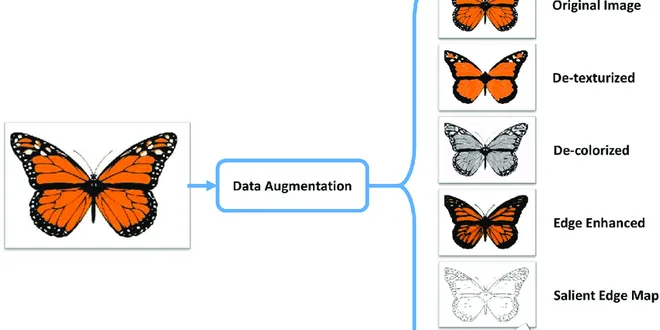
Maximizing the Impact of Data Augmentation: Effective Techniques and Best Practices
Data augmentation is a popular technique in machine learning that involves creating new data from existing data by making various modifications to it. These modifications could include adding noise…
📚 Read more at Towards AI🔎 Find similar documents

Data Augmentation: What, Why and How……
Data augmentation is a regularization technique like Lasso, Hinge, L1, and L2 regularizations, it also participates with great help during any machine learning model training process. In general…
📚 Read more at Analytics Vidhya🔎 Find similar documents

A Short Survey on Implicit Data Augmentation
Data augmentation is a popular technique used to increase the generalizability of a possibly overfitting model. By generating additional training data and exposing the model to different versions of…
📚 Read more at Towards Data Science🔎 Find similar documents

Data augmentation
Overview This tutorial demonstrates data augmentation: a technique to increase the diversity of your training set by applying random (but realistic) transformations, such as image rotation. You will l...
📚 Read more at TensorFlow Tutorials🔎 Find similar documents

Data Augmentations in Torchvision
This blog aims to compare and familiarise with different data transformations techniques used by the research community Image by author. Introduction Why do we need data augmentation? Data augmentati...
📚 Read more at Towards Data Science🔎 Find similar documents

How to Perform Data Augmentation in NLP Projects
A simple way to conduct Data Augmentation by using TextAttack Library Image by Gerd Altmann from Pixabay In machine learning, it is crucial to have a large amount of data in order to achieve strong m...
📚 Read more at Towards Data Science🔎 Find similar documents

Data Augmentation Techniques using OpenCV
Data augmentation is a strategy that enables practitioners to significantly increase the diversity of data available for training models, without actually collecting new data. Data augmentation…
📚 Read more at Analytics Vidhya🔎 Find similar documents

EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
Data Augmentation in Machine Learning is a popular technique to making robust and generalized ML models even in low availability of data kind of situations. It helps to increase the amount of…
📚 Read more at Towards Data Science🔎 Find similar documents