Distillation
Distillation is a powerful technique used in machine learning and artificial intelligence to simplify complex models while retaining their essential knowledge. This process involves transferring the knowledge from a larger, more cumbersome model, often referred to as the “teacher,” to a smaller, more efficient model known as the “student.” The goal is to create a compact model that performs comparably to the larger one but requires significantly less computational power. Distillation is particularly valuable in real-world applications where resource constraints are a concern, enabling the deployment of effective AI solutions across various industries.

Model Distillation
Making AI Models Leaner and Meaner: A go-to approach for small and medium businesses | Practical guide to shrinking AI Models without losing their Intelligence Image Source: Author 1\. Introduction A...
📚 Read more at Towards AI🔎 Find similar documents

What is Knowledge Distillation?
Knowledge distillation is a fascinating concept, we’ll cover briefly why we need it, how it works.
📚 Read more at Towards Data Science🔎 Find similar documents
Data Distillation for Object Detection
Knowledge distillation (KD), also known as model distillation (MD), is an impressive neural network training method proposed by the God Father of deep learning, Geoffrey Hinton, to gain neural…
📚 Read more at Towards Data Science🔎 Find similar documents

Smaller, Faster, Smarter: The Power of Model Distillation
Last week, we covered OpenAI’s new series of models: o1 . TL;DR: They trained the o1 models to use better reasoning by leveraging an improved chain of thought before replying. This made us think. Open...
📚 Read more at Towards AI🔎 Find similar documents
Using Distillation to Protect Your Neural Networks
Distillation is a hot research area. For distillation, you first train a deep learning model, the teacher network, to solve your task. Then, you train a student network, which can be any model. While…...
📚 Read more at Towards Data Science🔎 Find similar documents

Distill Hiatus
Over the past five years, Distill has supported authors in publishing artifacts that push beyond the traditional expectations of scientific papers. From Gabriel Goh’s interactive exposition of momentu...
📚 Read more at Distill🔎 Find similar documents
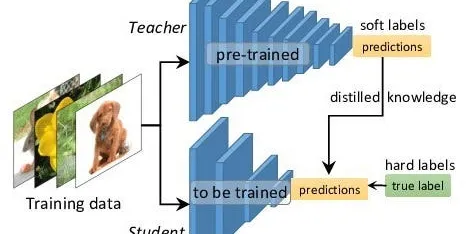
A Gentle Introduction to Hint Learning & Knowledge Distillation
Knowledge distillation is a method to distill the knowledge in an ensemble of cumbersome models and compress it into a single model in order to make possible deployments to real-life applications…
📚 Read more at Towards AI🔎 Find similar documents
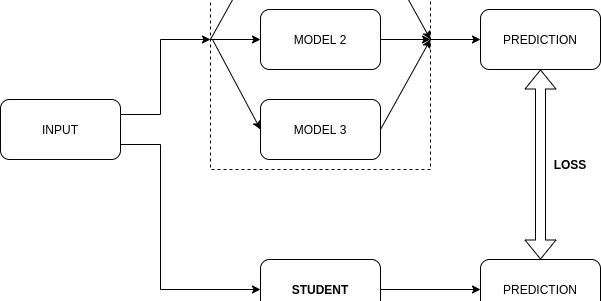
Knowledge Distillation for Object Detection 1: Start from simple classification model
Knowledge Distillation (KD) is a technique for improving accuracy of a small network (student), by transferring distilled knowledge produced by a large network (teacher). We can also say that KD is…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Distill Update 2018
Things that Worked Well Interfaces for Ideas Engagement as a Spectrum Software Engineering Best Practices for Scientific Publishing Challenges & Improvements The Distill Prize A Small Community Revie...
📚 Read more at Distill🔎 Find similar documents