Feature Versioning
Feature versioning is a crucial aspect of software development and data science that involves managing changes to features over time. It allows teams to track modifications, enhancements, or deprecations of features, ensuring that different versions of a product can coexist and function correctly. This practice is essential for maintaining compatibility, especially in environments where multiple users or systems rely on specific feature sets. By implementing feature versioning, developers can facilitate smoother updates, reduce the risk of introducing bugs, and enhance collaboration among team members, ultimately leading to more robust and user-friendly applications.

Feature Engineering
Feature engineering is a set of techniques applied in data science aiming to make sure the data can be used properly by models. It is a mix between science and art, and is arguably the most important…...
📚 Read more at Towards Data Science🔎 Find similar documents

Feature Engineering using Featuretools with code
Feature engineering, also known as feature creation, is the process of constructing new features from existing data to train a machine learning model. Typically, feature engineering is a drawn-out…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Feature engineering A-Z
Feature engineering is the process of transforming data to extract valuable information. In fact, if appropriately transformed, feature engineering can play even a bigger role in model performance…
📚 Read more at Towards Data Science🔎 Find similar documents

Let’s Do: Feature Engineering
Feature engineering can mean different things to different people, but the term largely covers the process of identifying, manipulating, and transforming information in order to improve the…
📚 Read more at Towards Data Science🔎 Find similar documents

Optimizing Feature generation
Feature generation is the process of creating new features from one or multiple existing features, potentially for use in statistical analysis. This process adds new information to be accessible…
📚 Read more at Towards Data Science🔎 Find similar documents
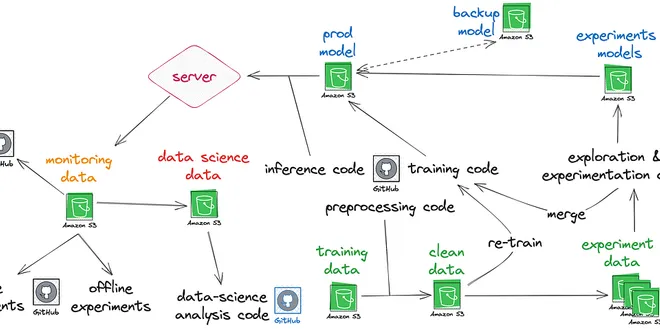
Branches Are All You Need: Our Opinionated ML Versioning Framework
A practical approach to versioning machine learning projects using Git Branches that simplifies workflows and organises data and models TL;DR A simple approach to versioning machine learning projects...
📚 Read more at Towards Data Science🔎 Find similar documents

Scaling Feature Engineering Pipelines with Feast and Ray
In a recent project involving the build of propensity models to predict customers’ prospective purchases, I encountered feature-engineering issues that I had seen numerous times before. These challeng...
📚 Read more at Level Up Coding🔎 Find similar documents

Stop One-Hot Encoding your Time-based Features
Feature Engineering is an essential component of the data science model development pipeline. A data scientist spends most of the time analyzing and preparing features to train a robust model. A raw…
📚 Read more at Towards Data Science🔎 Find similar documents

Feature Engineering — deep dive into Encoding and Binning techniques
Feature engineering is the most important aspect of a data science model development. There are several categories of features in a raw dataset. Features can be text, date/time, categorical, and…
📚 Read more at Towards Data Science🔎 Find similar documents

Use semantic versioning
Semantic versioning is a well-specified convention used by many software projects, although admittedly the extent to which the convention is followed can vary considerably between projects. In essenc...
📚 Read more at Java Best Practices🔎 Find similar documents

Use semantic versioning
Semantic versioning is a well-specified convention used by many software projects, although admittedly the extent to which the convention is followed can vary considerably between projects. In essence...
📚 Read more at Java Best Practices🔎 Find similar documents
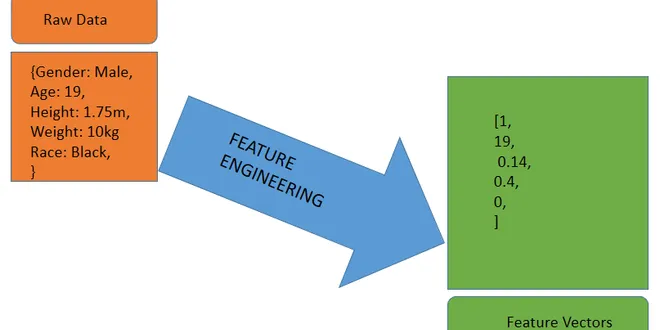
Feature Engineering Techniques
Feature engineering is one of the key steps in developing machine learning models. This involves any of the processes of selecting, aggregating, or extracting features from raw data with the aim of…
📚 Read more at Towards Data Science🔎 Find similar documents