K Means
K-Means is a widely used unsupervised machine learning algorithm designed for clustering data points into distinct groups. It operates by partitioning a dataset into K clusters, where each cluster is represented by its centroid, the mean of the points within that cluster. The algorithm iteratively assigns data points to the nearest centroid and recalculates the centroids until convergence is achieved. K-Means is valued for its simplicity and efficiency, making it suitable for various applications, including image segmentation, customer grouping, and data summarization. Its effectiveness lies in minimizing intra-cluster distances while maximizing inter-cluster distances.
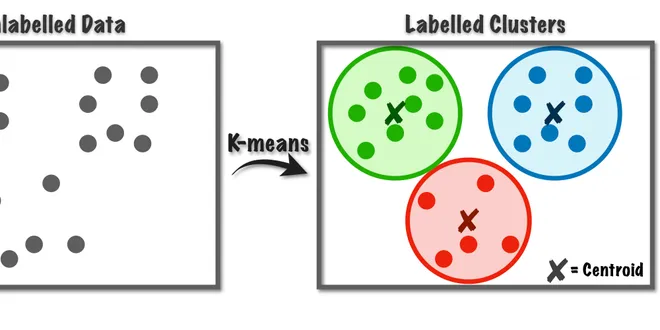
K-means: A Complete Introduction
K-means is an unsupervised clustering algorithm designed to partition unlabelled data into a certain number (thats the “ K”) of distinct groupings. In other words, k-means finds observations that…
📚 Read more at Towards Data Science🔎 Find similar documents

K-Means Explained
This article will outline a conceptual understanding of the k-Means algorithm and its associated python implementation using the sklearn library. K means is a clustering algorithm with many use cases…...
📚 Read more at Towards Data Science🔎 Find similar documents

“K-means Clustering” in 200 words.
K-means is a machine learning algorithm designed to find “clusters” in data by measuring the “distance” between points. This is typically done through the “elbow method” by plotting the “error” of…
📚 Read more at Analytics Vidhya🔎 Find similar documents
K-Means tricks for fun and profit
K-Means is an elegant algorithm. It’s easy to understand (make random points, move them iteratively to become centers of some existing clusters) and works well in practice. When I first learned about…...
📚 Read more at Towards Data Science🔎 Find similar documents

K Means without libraries — Python
Kmeans is a widely used clustering tool for analyzing and classifying data. Often times, however, I suspect, it is not fully understood what is happening under the hood. This isn’t necessarily a bad…
📚 Read more at Towards Data Science🔎 Find similar documents

K-means Clustering in a Nutshell
K-means is an unsupervised clustering machine learning model. In Unsupervised Learning, the data set does not contain a target value to train the data. Clustering is a technique in which we group…
📚 Read more at Towards AI🔎 Find similar documents

K-Means Practical
Unsupervised learning is often looked on as a little ‘unconventional’ in the data science world, especially when empirically provable results are desired. K-Means clustering enjoys some enduring…
📚 Read more at Towards Data Science🔎 Find similar documents

K-means from scratch with NumPy
K-means is the simplest clustering algorithm out there. It’s easy to understand and to implement, making it a great starting point when trying to understand the world of unsupervised learning…
📚 Read more at Towards Data Science🔎 Find similar documents

K-Means Clustering From Scratch
K-means clustering (referred to as just k-means in this article) is a popular unsupervised machine learning algorithm (unsupervised means that no target variable, a.k.a. Y variable, is required to…
📚 Read more at Towards Data Science🔎 Find similar documents

K Means Clustering with Python
K Means Clustering is an unsupervised machine learning algorithm. It takes in mixed data and divides the data into small groups/clusters based on the patterns in the data. In order to explain the…
📚 Read more at Towards Data Science🔎 Find similar documents

Revisiting k-Means: 3 Approaches to Make It Work Better
The k-means algorithm is a cornerstone of unsupervised machine learning, known for its simplicity and trusted for its efficiency in partitioning data into a predetermined number of clusters.
📚 Read more at MachineLearningMastery.com🔎 Find similar documents

K-means Clustering
K-means Clustering is an unsupervised machine learning technique. It aims to partition n observations into k clusters. As we have seen in other Machine learning Algorithms, we have a loss function…
📚 Read more at Analytics Vidhya🔎 Find similar documents