MapReduce
MapReduce is a programming model designed for processing and generating large data sets with a distributed algorithm on a cluster. It simplifies the complexities of parallelization, fault tolerance, and data distribution, allowing developers to focus on writing the core logic of their applications. The model consists of two main functions: the Map function, which processes input data and produces intermediate key-value pairs, and the Reduce function, which aggregates these pairs to produce a final output. This abstraction enables efficient data processing across multiple machines, making it a powerful tool for handling vast amounts of information in various applications.

Understanding MapReduce
MapReduce is a computing model for processing big data with a parallel, distributed algorithm on a cluster. It was invented by Google and has been largely used in the industry since 2004. Many…
📚 Read more at Better Programming🔎 Find similar documents

Introduction to MapReduce
MapReduce is a programming framework for distributed parallel processing of large jobs. It was first introduced by Google in 2004, and popularized by Hadoop. The primary motivation of MapReduce was…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Understanding MapReduce with the Help of Harry Potter
MapReduce is an algorithm that allows large data sets to be processed in parallel, i.e. on multiple computers simultaneously. This greatly accelerates queries for large data sets. MapReduce was…
📚 Read more at Towards Data Science🔎 Find similar documents

MapReduce: Simplified Data Processing on Large Clusters
MapReduce is an interface that enables automatic parallelization and distribution of large-scale computation while abstracting over “the messy details of parallelization, fault-tolerance, data…
📚 Read more at Level Up Coding🔎 Find similar documents
A Simple MapReduce in Go
Hadoop MapReduce is a software framework for easily writing applications that process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity…
📚 Read more at Level Up Coding🔎 Find similar documents

Processing Data At Scale With MapReduce
In the current market landscape, organizations must engage in data-driven decision-making to maintain competitiveness and foster innovation. As a result, an immense amount of data is collected on a da...
📚 Read more at Towards Data Science🔎 Find similar documents
Building a Book Recommendation Pipeline with LangGraph’s MapReduce Pattern
MapReduce is a way to process a list of items and combine the results into a single output. Continue reading on Towards AI
📚 Read more at Towards AI🔎 Find similar documents
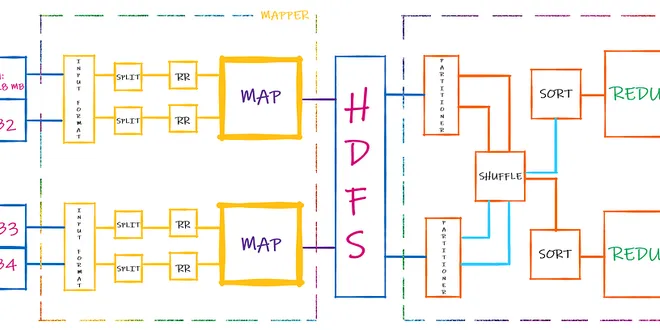
MapReduce
Simplifying the MapReduce Framework
📚 Read more at Towards Data Science🔎 Find similar documents
What is MapReduce good for?
I’m working on a video series for O’Reilly that aims to de-mystify Hadoop and MapReduce, explaining how mere mortals can analyze massive data sets. I’m recording the first drafts of my segments now, a...
📚 Read more at Pete Warden's blog🔎 Find similar documents
A MapReduce overview
When I first started reading about MapReduce, nearly every tutorial intro’d with a Java or C++ prerequisite reminder. Yet there’s also the outdated (and increasingly sparse) mindset in the tech world…...
📚 Read more at Towards Data Science🔎 Find similar documents

MapReduce for Idiots
Photo by Stuart Pilbrow I'll admit it, I was intimidated by MapReduce. I'd tried to read explanations of it, but even the wonderful Joel Spolsky left me scratching my head. So I plowed ahead trying to...
📚 Read more at Pete Warden's blog🔎 Find similar documents

How Map Reduce Let You Deal With PetaByte Scale With Ease
Map Reduce is the core idea used in systems which are used in todays world to analyse and manipulate PetaByte scale datasets (Spark, Hadoop). Knowing about the core concept gives a better…
📚 Read more at Analytics Vidhya🔎 Find similar documents