Model Serving Techniques
Model serving techniques are essential for deploying machine learning models into production environments, enabling them to deliver predictions in real-time. These techniques encompass various architectures and frameworks designed to handle the complexities of model deployment, including scalability, latency, and resource management. Different models may require distinct serving strategies based on their computational demands and application contexts. Common approaches include using dedicated serving frameworks like TensorFlow Serving and TorchServe, which facilitate the integration of models into applications as API endpoints. Understanding these techniques is crucial for ensuring efficient and effective model performance in real-world scenarios.

🍮 Edge#147: MLOPs – Model Serving
In this issue: we explain what model serving is; we explore the TensorFlow serving paper; we cover TorchServe, a super simple serving framework for PyTorch. 💡 ML Concept of the Day: Model Serving Con...
📚 Read more at TheSequence🔎 Find similar documents

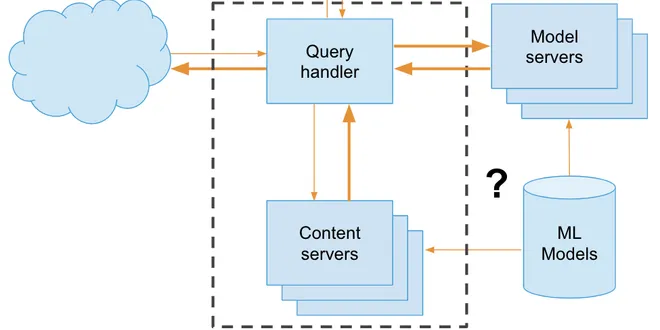
Model serving architectures
Lecture 5 of MLOps with Databricks course
📚 Read more at Marvelous MLOps Substack🔎 Find similar documents

🌀Edge#12: The challenges of Model Serving~
In this issue: we explain the concept of model serving; we review a paper in which Google Research outlined the architecture of a serving pipeline for TensorFlow models; we discuss MLflow, one of the ...
📚 Read more at TheSequence🔎 Find similar documents

Serving ML Models with TorchServe
A complete end-to-end example of serving an ML model for image classification task Image by author Motivation This post will walk you through a process of serving your deep learning Torch model with ...
📚 Read more at Towards Data Science🔎 Find similar documents
Stateful model serving: how we accelerate inference using ONNX Runtime
Stateless model serving is what one usually thinks about when using a machine-learned model in production. For instance, a web application handling live traffic can call out to a model server from…
📚 Read more at Towards Data Science🔎 Find similar documents

101 For Serving ML Models
Learn to write robust APIs Me at Spiti Valley in Himachal Pradesh → ML in production series Productionizing NLP Models 10 Useful ML Practices For Python Developers Serving ML Models My love for unders...
📚 Read more at Pratik’s Pakodas 🍿🔎 Find similar documents

Model serving architectures on Databricks
Many different components are required to bring machine learning models to production. I believe that machine learning teams should aim to simplify the architecture and minimize the amount of tools th...
📚 Read more at Marvelous MLOps Substack🔎 Find similar documents

Serving TensorFlow models with TensorFlow Serving
TensorFlow Serving is a flexible, high-performance serving system for machine learning models, designed for production environments.
📚 Read more at Towards Data Science🔎 Find similar documents

Several Ways for Machine Learning Model Serving (Model as a Service)
No matter how well you build a model, no one knows it if you cannot ship model. However, lots of data scientists want to focus on model building and skipping the rest of the stuff such as data…
📚 Read more at Towards AI🔎 Find similar documents

Deploying PyTorch Models with Nvidia Triton Inference Server
Machine Learning’s (ML) value is truly recognized in real-world applications when we arrive at Model Hosting and Inference . It’s hard to productionize ML workloads if you don’t have a highly performa...
📚 Read more at Towards Data Science🔎 Find similar documents

Serving a model using MLflow
The mlflow models serve command stops as soon as you press Ctrl+C or exit the terminal. If you want the model to be up and running, you need to create a systemd service for it. Go into the…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Scaling Machine Learning models using Tensorflow Serving & Kubernetes
Tensorflow serving is an amazing tool to put your models into production from handling requests to effectively using GPU for multiple models. The problem arises when the number of requests increases…
📚 Read more at Towards Data Science🔎 Find similar documents