Momentum optimizers
Momentum optimizers are advanced techniques used in training neural networks to enhance the efficiency of the optimization process. By incorporating a temporal element, these optimizers help accelerate convergence and avoid local minima, which can hinder learning. The core idea is to maintain a velocity vector that accumulates past gradients, allowing the optimizer to move more smoothly across the loss landscape. This approach not only speeds up the training but also improves the model’s ability to navigate complex terrains in high-dimensional spaces. Common momentum optimizers include classical momentum and Nesterov accelerated gradient, each with unique benefits for model training.

Momentum: A simple, yet efficient optimizing technique
What are gradient descent, moving average and how can they be applied to optimize Neural Networks? How is Momentum better than gradient Descent?
📚 Read more at Analytics Vidhya🔎 Find similar documents

Why to Optimize with Momentum
Momentum optimiser and its advantages over Gradient Descent
📚 Read more at Analytics Vidhya🔎 Find similar documents

Optimizers — Momentum and Nesterov momentum algorithms (Part 2)
Welcome to the second part on optimisers where we will be discussing momentum and Nesterov accelerated gradient. If you want a quick review of vanilla gradient descent algorithms and its variants…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Why 0.9? Towards Better Momentum Strategies in Deep Learning.
Momentum is a widely-used strategy for accelerating the convergence of gradient-based optimization techniques. Momentum was designed to speed up learning in directions of low curvature, without…
📚 Read more at Towards Data Science🔎 Find similar documents

Why Momentum Really Works
Here’s a popular story about momentum [1, 2, 3] : gradient descent is a man walking down a hill. He follows the steepest path downwards; his progress is slow, but steady. Momentum is a heavy ball rol...
📚 Read more at Distill🔎 Find similar documents

Optimizers
Optimizers What is Optimizer ? It is very important to tweak the weights of the model during the training process, to make our predictions as correct and optimized as possible. But how exactly do you ...
📚 Read more at Machine Learning Glossary🔎 Find similar documents

Optimizers: Gradient Descent, Momentum, Adagrad, NAG, RMSprop, Adam
In this article, we will learn about optimization techniques to speed up the training process and improve the performance of machine learning and neural network models. The gradient descent and optimi...
📚 Read more at Level Up Coding🔎 Find similar documents

Optimizers Explained - Adam, Momentum and Stochastic Gradient Descent
Picking the right optimizer with the right parameters, can help you squeeze the last bit of accuracy out of your neural network model.
📚 Read more at Machine Learning From Scratch🔎 Find similar documents

Optimizers
In machine/deep learning main motive of optimizers is to reduce the cost/loss by updating weights, learning rates and biases and to improve model performance. Many people are already training neural…
📚 Read more at Towards Data Science🔎 Find similar documents

Deep Learning Optimizers
This blog post explores how the advanced optimization technique works. We will be learning the mathematical intuition behind the optimizer like SGD with momentum, Adagrad, Adadelta, and Adam…
📚 Read more at Towards Data Science🔎 Find similar documents
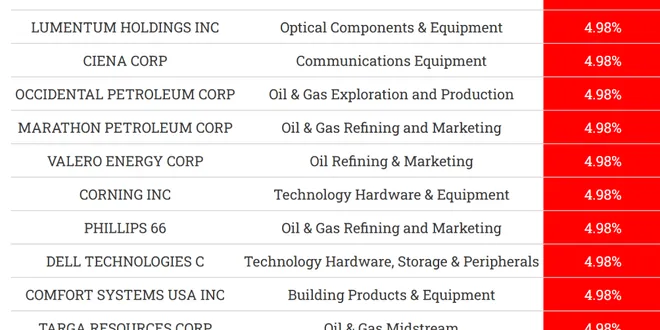
Momentum Investing Enhanced by Microsoft Foundry-Hosted Large Language Model
LLM-enhanced momentum investing combines traditional momentum signals with real-time news interpretation by large language models (LLMs). The idea is straightforward: stocks with strong past returns a...
📚 Read more at R-bloggers🔎 Find similar documents