Momentum
Momentum is a fundamental concept in optimization techniques, particularly in machine learning and deep learning. It refers to a method that enhances the efficiency of gradient descent algorithms by incorporating the past gradients to accelerate convergence. By maintaining a velocity vector that accumulates past gradients, momentum helps to navigate through the loss landscape more effectively, reducing oscillations and improving stability. This technique is especially beneficial in scenarios with noisy data, allowing models to learn more robustly. Overall, momentum serves as a powerful tool for optimizing neural networks and improving their performance in various applications.

Why Momentum Really Works
Here’s a popular story about momentum [1, 2, 3] : gradient descent is a man walking down a hill. He follows the steepest path downwards; his progress is slow, but steady. Momentum is a heavy ball rol...
📚 Read more at Distill🔎 Find similar documents

Momentum is Gradient Descent on Gradients
Everyone uses momentum. Almost nobody knows what it actually does. Continue reading on Python in Plain English
📚 Read more at Python in Plain English🔎 Find similar documents

Why 0.9? Towards Better Momentum Strategies in Deep Learning.
Momentum is a widely-used strategy for accelerating the convergence of gradient-based optimization techniques. Momentum was designed to speed up learning in directions of low curvature, without…
📚 Read more at Towards Data Science🔎 Find similar documents
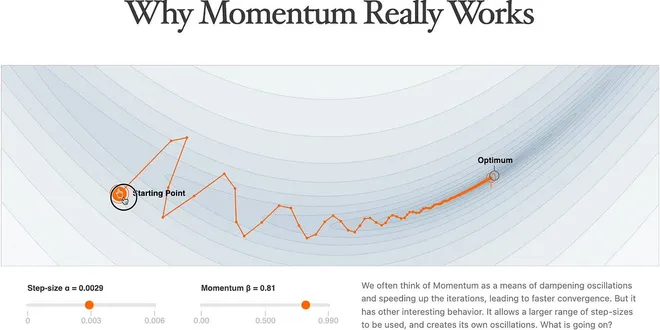
An Intuitive and Visual Demonstration of Momentum in Machine Learning
Speedup machine learning model training with little effort.
📚 Read more at Daily Dose of Data Science🔎 Find similar documents

Momentum: A simple, yet efficient optimizing technique
What are gradient descent, moving average and how can they be applied to optimize Neural Networks? How is Momentum better than gradient Descent?
📚 Read more at Analytics Vidhya🔎 Find similar documents

Why to Optimize with Momentum
Momentum optimiser and its advantages over Gradient Descent
📚 Read more at Analytics Vidhya🔎 Find similar documents
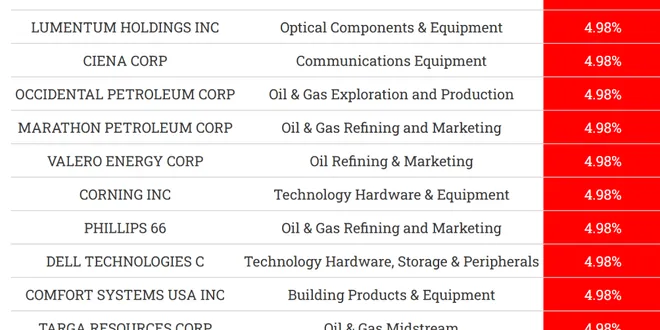
Momentum Investing Enhanced by Microsoft Foundry-Hosted Large Language Model
LLM-enhanced momentum investing combines traditional momentum signals with real-time news interpretation by large language models (LLMs). The idea is straightforward: stocks with strong past returns a...
📚 Read more at R-bloggers🔎 Find similar documents
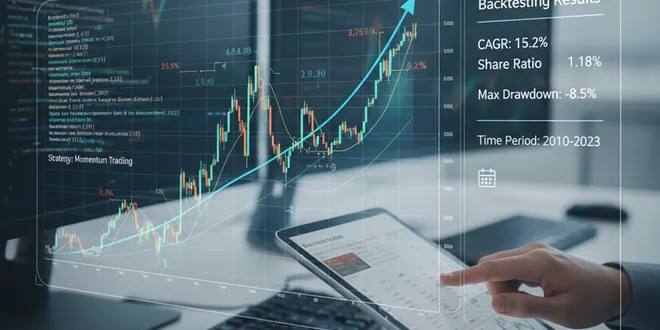
Leveraging Momentum: Build Your Active Trading Strategy
So far in our series, we’ve optimized a portfolio based on historical risk and return (MPT) and then deconstructed its performance using the Fama-French factors . Today, we go from analyzing past retu...
📚 Read more at Python in Plain English🔎 Find similar documents
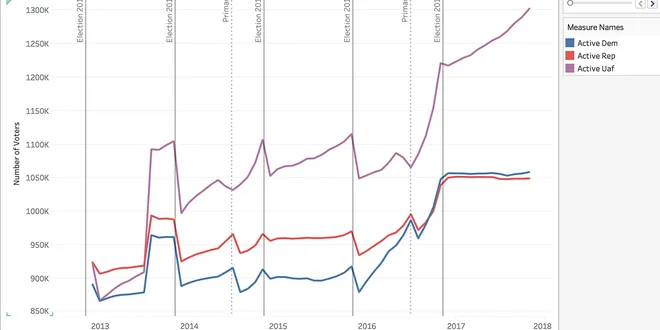
Quantifying Political Momentum with Data
Political commentators get paid to talk about the current political landscape every day, and while watching these talking heads do their thing on TV, I always hear the words “Political Momentum” over…...
📚 Read more at Towards Data Science🔎 Find similar documents

From Standstill to Momentum: MLP as Your First Gear in tidymodels
Embarking on a machine learning journey often feels like being handed the keys to a high-end sports car. The possibilities seem endless, the power under the hood palpable, and the anticipation of spee...
📚 Read more at R-bloggers🔎 Find similar documents
Algorithmic Momentum Trading Strategy
Infusing Big Data + Machine Learning & Technical Indicators for a Robust Algorithmic Momentum Trading Strategy Big data is completely revolutionizing how the stock markets across the world are…
📚 Read more at Analytics Vidhya🔎 Find similar documents

The Generative Audio Momentum
Next Week in The Sequence: Edge 303: Our series about new methods in generative AI continues with an exploration of different retrieval-augmented foundation model techniques. We discuss Meta AI’s famo...
📚 Read more at TheSequence🔎 Find similar documents