Parameter Norm Penalties
Parameter norm penalties are techniques used in machine learning and optimization to regularize models by discouraging overly complex parameter values. By applying penalties based on the norms of the parameters, such as L1 (Lasso) or L2 (Ridge) regularization, these methods help prevent overfitting and improve generalization to unseen data. The penalties effectively constrain the model’s capacity, promoting simpler solutions that maintain predictive performance. This approach is particularly useful in high-dimensional spaces, where the risk of overfitting is heightened. Understanding and implementing parameter norm penalties can significantly enhance the robustness of machine learning models.

Prevent Parameter Pollution in Node.JS
HTTP Parameter Pollution or HPP in short is a vulnerability that occurs due to passing of multiple parameters having the same name. HTTP Parameter Pollution or HPP in short is a vulnerability that…
📚 Read more at Level Up Coding🔎 Find similar documents

SGD: Penalties
SGD: Penalties Contours of where the penalty is equal to 1 for the three penalties L1, L2 and elastic-net. All of the above are supported by SGDClassifier and SGDRegressor .
📚 Read more at Scikit-learn Examples🔎 Find similar documents

Parameter Constraints & Significance
Setting the values of one or more parameters for a GARCH model or applying constraints to the range of permissible values can be useful. Continue reading: Parameter Constraints & Significance
📚 Read more at R-bloggers🔎 Find similar documents

UninitializedParameter
A parameter that is not initialized. Unitialized Parameters are a a special case of torch.nn.Parameter where the shape of the data is still unknown. Unlike a torch.nn.Parameter , uninitialized paramet...
📚 Read more at PyTorch documentation🔎 Find similar documents
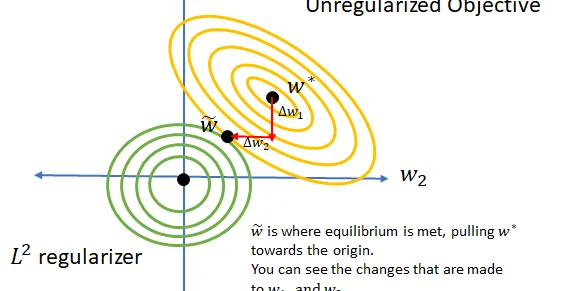
Norms, Penalties, and Multitask learning
A regularizer is commonly used in machine learning to constrain a model’s capacity to cerain bounds either based on a statistical norm or on prior hypotheses. This adds preference for one solution…
📚 Read more at Towards Data Science🔎 Find similar documents

Parametrizations Tutorial
Implementing parametrizations by hand Assume that we want to have a square linear layer with symmetric weights, that is, with weights X such that X = Xᵀ . One way to do so is to copy the upper-triangu...
📚 Read more at PyTorch Tutorials🔎 Find similar documents

Parameter Servers
As we move from a single GPU to multiple GPUs and then to multiple servers containing multiple GPUs, possibly all spread out across multiple racks and network switches, our algorithms for distributed ...
📚 Read more at Dive intro Deep Learning Book🔎 Find similar documents

Parameter
A kind of Tensor that is to be considered a module parameter. Parameters are Tensor subclasses, that have a very special property when used with Module s - when they’re assigned as Module attributes t...
📚 Read more at PyTorch documentation🔎 Find similar documents
Too Many Parameters? Use This Pattern
🧱 Build software that lasts. Join the Software Design Mastery waiting list → https://arjan.codes/mastery. Functions with long parameter lists often become harder to understand and maintain as a codeb...
📚 Read more at ArjanCodes🔎 Find similar documents

ParametrizationList
A sequential container that holds and manages the original or original0 , original1 , … parameters or buffers of a parametrized torch.nn.Module . It is the type of module.parametrizations[tensor_name]...
📚 Read more at PyTorch documentation🔎 Find similar documents

L1 Penalty and Sparsity in Logistic Regression
L1 Penalty and Sparsity in Logistic Regression Comparison of the sparsity (percentage of zero coefficients) of solutions when L1, L2 and Elastic-Net penalty are used for different values of C. We can ...
📚 Read more at Scikit-learn Examples🔎 Find similar documents