Quantization
Quantization is a crucial technique in deep learning that involves converting a model’s parameters, such as weights and biases, from high-precision data types to lower-precision formats. This process, which typically reduces 32-bit floating point values to 8-bit integers, aims to decrease the model’s memory footprint and computational requirements. By sacrificing a small amount of numerical precision, quantization enables models to run more efficiently on various devices, from powerful data centers to smartphones. It encompasses methods like Post-Training Quantization and Quantization-Aware Training, each with its own advantages and trade-offs, making it essential for deploying modern AI applications effectively.

Quantization
This file is in the process of migration to torch/ao/quantization , and is kept here for compatibility while the migration process is ongoing. If you are adding a new entry/functionality, please, add ...
📚 Read more at PyTorch documentation🔎 Find similar documents

Using Quantized Models with Ollama for Application Development
Quantization is a frequently used strategy applied to production machine learning models, particularly large and complex ones, to make them lightweight by reducing the numerical precision of the model...
📚 Read more at MachineLearningMastery.com🔎 Find similar documents
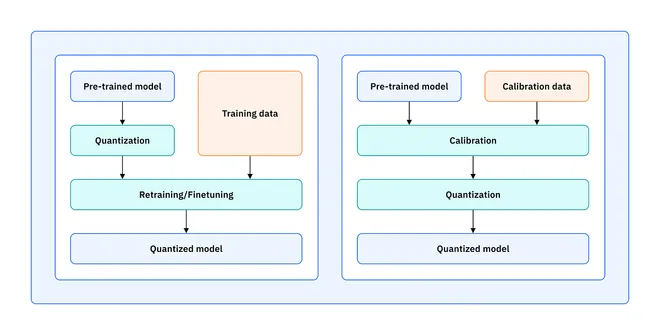
Quantization: How to Accelerate Big AI Models
In the world of deep learning, we are in an arms race for bigger, more powerful models. While this has led to incredible capabilities, it has also created a significant problem: these models are enorm...
📚 Read more at Towards AI🔎 Find similar documents

Dynamic Quantization
Introduction There are a number of trade-offs that can be made when designing neural networks. During model development and training you can alter the number of layers and number of parameters in a re...
📚 Read more at PyTorch Tutorials🔎 Find similar documents

Dynamic Quantization
Introduction There are a number of trade-offs that can be made when designing neural networks. During model developmenet and training you can alter the number of layers and number of parameters in a r...
📚 Read more at PyTorch Tutorials🔎 Find similar documents
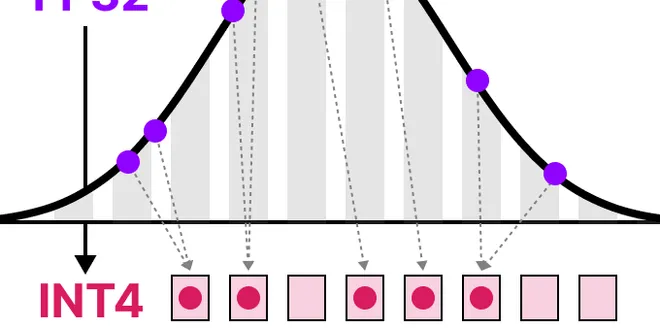
A Visual Guide to Quantization
Demystifying the compression of large language models As their name suggests, Large Language Models (LLMs) are often too large to run on consumer hardware. These models may exceed billions of paramet...
📚 Read more at Towards Data Science🔎 Find similar documents

quantize
Quantize the input float model with post training static quantization. First it will prepare the model for calibration, then it calls run_fn which will run the calibration step, after that we will con...
📚 Read more at PyTorch documentation🔎 Find similar documents
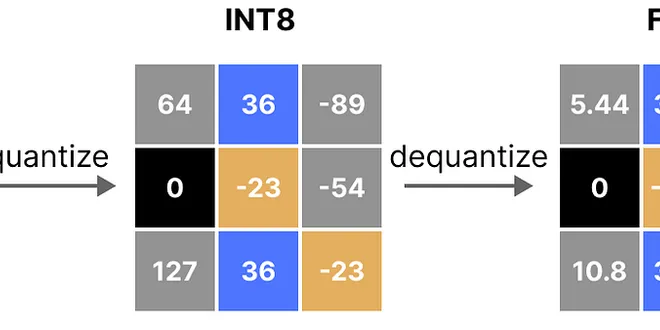
Quantization in Machine Learning and Large Language Models
In this blog, we’ll dive deep into the different types of quantization, their significance, and practical examples to illustrate how they work. Numerical demonstrations are also included for better cl...
📚 Read more at Towards AI🔎 Find similar documents

LLM Quantization Techniques- GPTQ
Recent advances in neural network technology have dramatically increased the scale of the model, resulting in greater sophistication and intelligence. Large Language Models (LLMs) have received high p...
📚 Read more at Towards AI🔎 Find similar documents
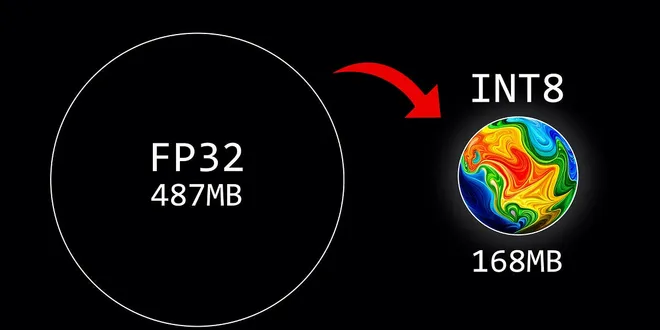
Introduction to Weight Quantization
Reducing the size of Large Language Models with 8-bit quantization Large Language Models (LLMs) are known for their extensive computational requirements. Typically, the size of a model is calculated ...
📚 Read more at Towards Data Science🔎 Find similar documents
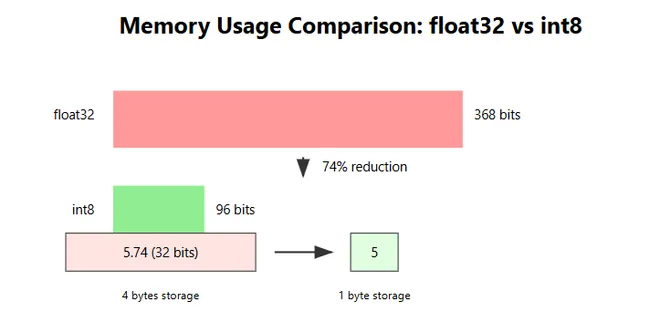
Quantization: Making AI Models Lighter Without Sacrificing Performance
Behind Pay-Wall? Click here Medium Edit description medium.com The Weight of Intelligence Imagine trying to fit an elephant into a compact car. That’s similar to AI developers' challenges when deployi...
📚 Read more at Python in Plain English🔎 Find similar documents

Quantization API Reference
torch.quantization This module contains Eager mode quantization APIs. Top level APIs Quantize the input float model with post training static quantization. Converts a float model to dynamic (i.e. Do q...
📚 Read more at PyTorch documentation🔎 Find similar documents