ReLu
ReLU, or Rectified Linear Unit, is a widely used activation function in neural networks that introduces non-linearity into the model. It operates by outputting the input directly if it is positive, and zero otherwise, effectively acting as a switch that allows only useful signals to pass through. This simplicity contributes to its popularity, as it helps mitigate issues like vanishing gradients, enabling faster training and improved performance. ReLU is particularly effective in deep learning applications, where it can enhance model accuracy and efficiency, making it a fundamental component in modern neural network architectures.

ReLU
Applies the rectified linear unit function element-wise: ReLU ( x ) = ( x ) + = max ( 0 , x ) \text{ReLU}(x) = (x)^+ = \max(0, x) ReLU ( x ) = ( x ) + = max ( 0 , x ) inplace ( bool ) – can optional...
📚 Read more at PyTorch documentation🔎 Find similar documents
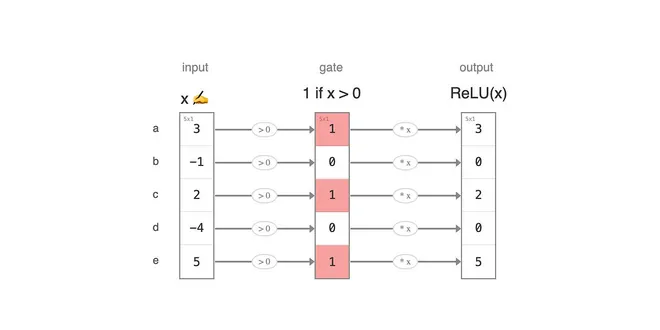
ReLU
Essential AI Math Excel Blueprints
📚 Read more at AI by Hand ✍️🔎 Find similar documents

A Gentle Introduction to the Rectified Linear Unit (ReLU)
Last Updated on August 20, 2020 In a neural network, the activation function is responsible for transforming the summed weighted input from the node into the activation of the node or output for that ...
📚 Read more at Machine Learning Mastery🔎 Find similar documents

Rectified Linear Unit (ReLU) Function in Machine Learning
Guide to Rectified Linear Unit Activation Function Continue reading on Level Up Coding
📚 Read more at Level Up Coding🔎 Find similar documents
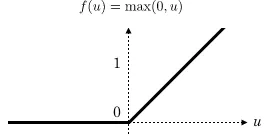
How ReLU works?
Since the 2012 publication of the AlexNet paper, by Ilya Krizhevsky and Geoffrey Hinton, the true potential of the neural networks began to unravel by itself. A major part of it is the ReLU…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Is GELU, the ReLU successor ?
Is GELU the ReLU Successor? Photo by Willian B. on Unsplash Can we combine regularization and activation functions? In 2016 a paper from authors Dan Hendrycks and Kevin Gimpel came out. Since then, t...
📚 Read more at Towards AI🔎 Find similar documents

ReLU Activation : Increase accuracy by being Greedy!
This article will help you decide where exactly to use ReLU (Rectified Linear Unit) and how it plays a role in increasing the accuracy of your model. Use this GitHub link to view the source code. The…...
📚 Read more at Analytics Vidhya🔎 Find similar documents
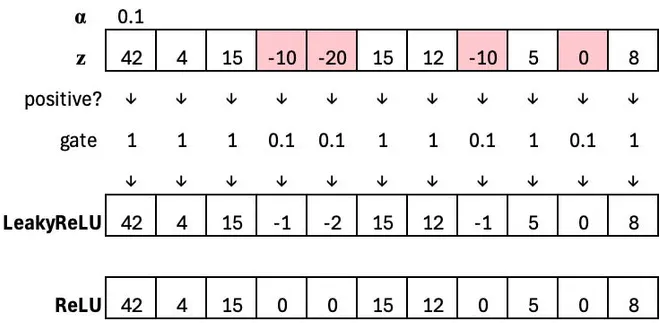
Leaky ReLU
Essential AI Math Excel Blueprints
📚 Read more at AI by Hand ✍️🔎 Find similar documents
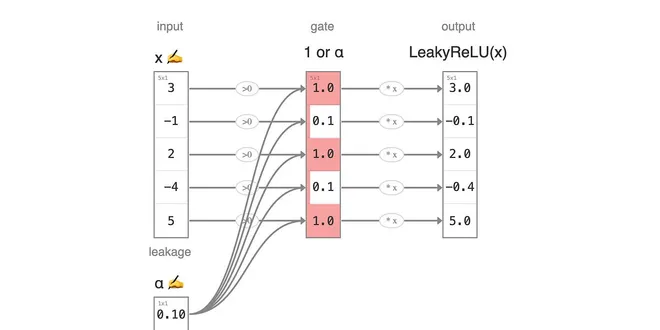
Leaky ReLU
Activation series · 2 of 4
📚 Read more at AI by Hand ✍️🔎 Find similar documents

ReLU Rules: Let’s Understand Why Its Popularity Remains Unshaken
For anybody who is just knocking on the door of Deep Learning or is a seasoned practitioner of it, ReLU is as commonplace as air. Air is exceptionally necessary for our survival, but are ReLUs that…
📚 Read more at Towards Data Science🔎 Find similar documents
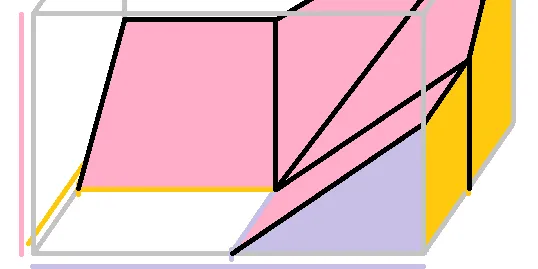
Neural Networks: an Alternative to ReLU
Above is a graph of activation (pink) for two neurons (purple and orange) using a well-trod activation function: the Rectified Linear Unit, or ReLU. When each neuron’s summed inputs increase, the…
📚 Read more at Towards Data Science🔎 Find similar documents