clustering
Clustering is an unsupervised machine learning technique that involves grouping a set of unlabeled data points into clusters based on their similarities. This method helps to identify patterns and structures within data, making it easier to analyze and interpret. Clustering can be applied in various fields, such as marketing for customer segmentation, computer vision for image segmentation, and biology for analyzing gene expression data. There are different approaches to clustering, including hard and soft clustering, which determine how data points are assigned to groups. Overall, clustering is a powerful tool for organizing and understanding complex datasets.

Clustering Instability
Clustering is an unsupervised learning technique used to create clusters of data points. An example is customer segmentation in marketing. There are several clustering algorithms available. However…
📚 Read more at Towards Data Science🔎 Find similar documents

Understanding Clustering
Clustering is an unsupervised learning technique to extract natural groupings or labels from predefined classes and prior information. This is an important technique to use for Exploratory Data…
📚 Read more at Towards Data Science🔎 Find similar documents

Clustering : What it is? When to use it?
Clustering is a Supervised Machine Learning technique whose aim is to group the data points having similar properties and/or features. K-means/ K-means++ /DBSCAN/ Data Science/ Python/ Daksh Trehan/Ma...
📚 Read more at Towards AI🔎 Find similar documents

K-Means Clustering: Simple intuition
What is Clustering? Clustering is a sort of a task where each data point is clubbed with “Similar” data points and they form one cluster. In other words, data points in one cluster or group are very…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Spectral clustering
Clustering is a widely used unsupervised learning method. The grouping is such that points in a cluster are similar to each other, and less similar to points in other clusters. Thus, it is up to the…
📚 Read more at Towards Data Science🔎 Find similar documents
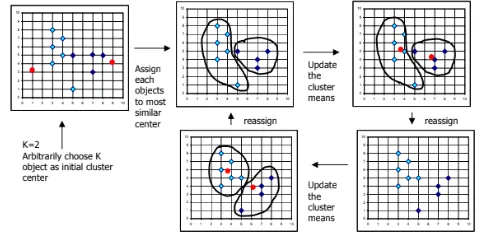
Data Mining → Clustering
Clustering is the grouping of particular set of objects or entity based on their characteristics and aggregating them according to their similarities. Clustering is similar to Classification, data…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Unlocking the Power of Clustering: A Beginner’s Guide
Clustering is an unsupervised machine learning technique that involves dividing a set of unlabeled samples into groups, or clusters, based on their similarity. Introduction Clustering is a way to gro...
📚 Read more at Towards Data Science🔎 Find similar documents
Clustering Using OPTICS
Clustering is a powerful unsupervised knowledge discovery tool used today, which aims to segment your data points into groups of similar features. However, each algorithm is pretty sensitive to the…
📚 Read more at Towards Data Science🔎 Find similar documents
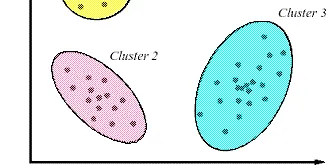
Hierarchical Clustering
Clustering is an unsupervised machine learning technique. In this blog article, we will be covering the following topics:- Clustering is the process of grouping data points based on similarity such…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Overview of Clustering Algorithms
Clustering is an unsupervised technique in which the set of similar data points is grouped together to form a cluster. A Cluster is said to be good if the intra-cluster (the data points within the…
📚 Read more at Towards Data Science🔎 Find similar documents

Clustering Data
To put it simply, clustering data is dividing up data points into groups of data in such a manner that we segregate groups with similar traits and assign them to clusters. Why would we do this? Well…
📚 Read more at Analytics Vidhya🔎 Find similar documents

When Clustering Doesn’t Make Sense
Clustering is one of the most widely used forms of unsupervised learning. It’s a great tool for making sense of unlabeled data and for grouping data into similar groups. A powerful clustering…
📚 Read more at Towards Data Science🔎 Find similar documents