dummy dataset
A dummy dataset is a synthetic collection of data created for testing, training, or evaluating machine learning models and algorithms. These datasets are particularly useful when real data is scarce, sensitive, or difficult to obtain. By generating dummy data, data professionals can simulate various scenarios, ensuring their models perform well under different conditions. Dummy datasets can be created using various methods in programming languages like Python, including libraries such as Scikit-learn. This approach allows for flexibility in data manipulation and helps identify potential issues without compromising the privacy of real-world data.

Simple ways to create synthetic dataset in Python
When developing a code, sometimes we need a dummy dataset. For instance, we want to share code and the underlying data but real-life dataset is confidential so not suitable for sharing. One option is…...
📚 Read more at Towards Data Science🔎 Find similar documents

Dummy Classifier Explained: A Visual Guide with Code Examples for Beginners
Setting the bar in machine learning with simple baseline models All illustrations in this article were created by author, incorporating licensed design elements from Canva Pro. Have you ever wondered...
📚 Read more at Towards Data Science🔎 Find similar documents

How to generate dummy data in Python
It doesn’t matter if you are a veteran data scientist or simply an aspiring data enthusiast, you would probably be looking for a dataset at some point to jumpstart a data science or machine learning…
📚 Read more at Towards Data Science🔎 Find similar documents

It’s Okay To Not Have Appropriate Data. Just Create It Yourself.
Two cool ways to create dummy datasets. Photo by Alice Dietrich on Unsplash Usually, for executing/testing a pipeline, we need to provide it with some dummy data. However, finding a good dataset can ...
📚 Read more at Towards Data Science🔎 Find similar documents
How to Generate Dummy Data with Python?
A guide on generating dummy data using the Faker library. Continue reading on Python in Plain English
📚 Read more at Python in Plain English🔎 Find similar documents

Generating a Synthetic Dataset for Machine Learning and Software Testing
Using Python to generate statistically similar dummy datasets for use in code development and testing robustness Continue reading on Towards Data Science
📚 Read more at Towards Data Science🔎 Find similar documents
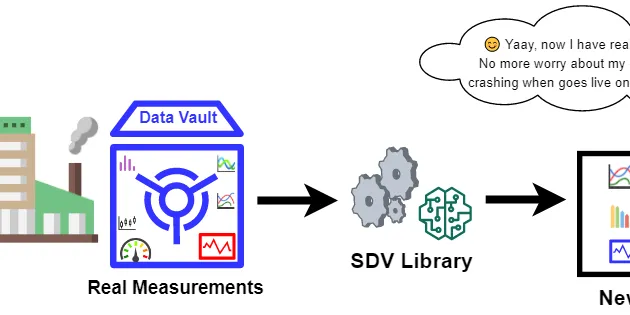
Synthetic Data Vault (SDV): A Python Library for Dataset Modeling
In data science, you usually need a realistic dataset to test your proof of concept. Creating fake data that captures the behavior of the actual data may sometimes be a rather tricky task. Several…
📚 Read more at Towards Data Science🔎 Find similar documents

How to Create a Custom Dataset in R
Make your own synthetic dataset to analyze for your portfolio Photo by Scott Graham on Unsplash In your data science journey, you might have come across synthetic datasets, sometimes called toy or du...
📚 Read more at Towards Data Science🔎 Find similar documents

The Good, The Bad, and the Ugly of Pd.Get_Dummies
A simple dataset for demonstration Here we have a simple dataset that includes a categorical feature called OS. The OS column lists computer operating systems. We will use this fictional data for purp...
📚 Read more at Towards Data Science🔎 Find similar documents

How to deal with imbalanced datasets
It is a dataset in which the examples are unequally distributed (i.e., most examples are from a class, while in the other class or classes are much fewer). Some examples are fraud detection or…
📚 Read more at Towards AI🔎 Find similar documents

Creating Your Own Sample Dataset from Python!
Quickly generate thousands of rows of data for your analysis Often, when we need to do a quick analysis, we will need to test this on a sample datasets. These datasets usually come from a certain sou...
📚 Read more at Python in Plain English🔎 Find similar documents

Datasets
The examples in this book use several datasets that are available either through scikit-learn or seaboarn . Those datasets are described briefly below. Boston Housing The Boston housing dataset conta...
📚 Read more at Machine Learning from Scratch Book🔎 Find similar documents