encoder transformers
Encoder transformers are a pivotal component of the transformer architecture, which revolutionized natural language processing and other fields. They utilize self-attention mechanisms to process input sequences, allowing the model to weigh the importance of different tokens in relation to one another. This enables the encoder to capture contextual information effectively. The architecture typically includes layers for embedding, positional encoding, multi-head attention, and feed-forward networks, all of which work together to transform input data into meaningful representations. Encoder transformers are widely used in tasks such as text classification, translation, and summarization, showcasing their versatility and power in deep learning applications.

TransformerEncoder
TransformerEncoder is a stack of N encoder layers. Users can build the BERT( https://arxiv.org/abs/1810.04805 ) model with corresponding parameters. encoder_layer – an instance of the TransformerEncod...
📚 Read more at PyTorch documentation🔎 Find similar documents

Text Classification with Transformer Encoders
Transformer is, without a doubt, one of the most important breakthroughs in the field of deep learning. The encoder-decoder architecture of this model has proven to be powerful in cross-domain applica...
📚 Read more at Towards Data Science🔎 Find similar documents

Implementing a Transformer Encoder from Scratch with JAX and Haiku
Understanding the fundamental building blocks of Transformers. Transformers, in the style of Edward Hopper (generated by Dall.E 3) Introduced in 2017 in the seminal paper “Attention is all you need”[...
📚 Read more at Towards Data Science🔎 Find similar documents

End to End Transformer Architecture — Encoder Part
In almost all state-of-the-art NLP models like Bert, GPT, T5, and in many variants, a transformer is used. sometimes we use only the encoder (Bert) of the transformer or just the decoder (GPT). In…
📚 Read more at Analytics Vidhya🔎 Find similar documents

TransformerEncoderLayer
TransformerEncoderLayer is made up of self-attn and feedforward network. This standard encoder layer is based on the paper “Attention Is All You Need”. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob...
📚 Read more at PyTorch documentation🔎 Find similar documents

TransformerDecoder
TransformerDecoder is a stack of N decoder layers decoder_layer – an instance of the TransformerDecoderLayer() class (required). num_layers – the number of sub-decoder-layers in the decoder (required)...
📚 Read more at PyTorch documentation🔎 Find similar documents

The Transformer Architecture From a Top View
There are two components in a Transformer Architecture: the Encoder and the Decoder. These components work in conjunction with each other and they share several similarities. Encoder : Converts an inp...
📚 Read more at Towards AI🔎 Find similar documents
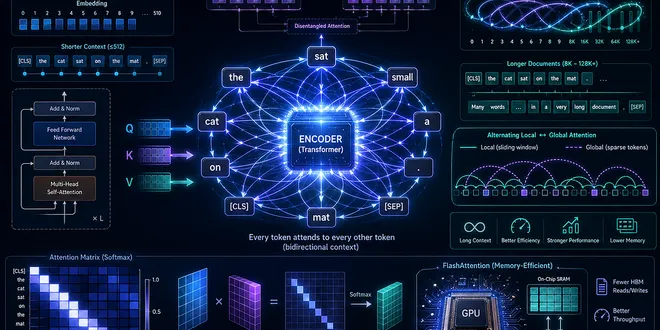
How Encoder Transformers Actually Understand Language
The evolution of the attention mechanism in encoder only models. From BERT to ModernBERT The AI world is currently obsessed with models that talk. GPT-4, Claude 3, and Llama have become the charismat...
📚 Read more at Towards AI🔎 Find similar documents

Transformers Positional Encodings Explained
In the original transformer architecture, positional encodings were added to the input and output embeddings. Encoder-Decoder Transformer architecture. Positional encodings play a crucial role in tran...
📚 Read more at Towards AI🔎 Find similar documents

The Position Encoding In Transformers!
Transformers and the self-attention are powerful architectures to enable large language models, but we need a mechanism for them to understand the order of the different tokens we input into the model...
📚 Read more at The AiEdge Newsletter🔎 Find similar documents
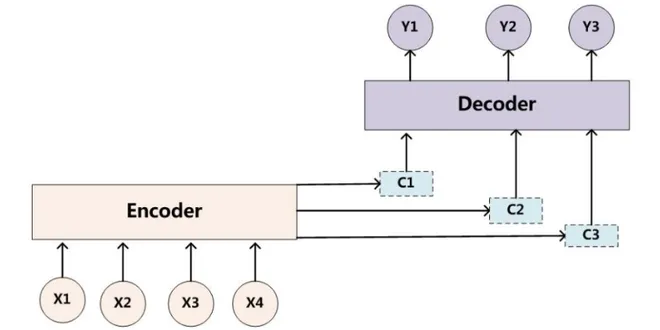
The Comparison between the Encoder and the Decoder
This article primarily discusses the advantages and disadvantages of large language models based on encoder and decoder architectures. Both the encoder and decoder architectures are built upon the Tra...
📚 Read more at Towards AI🔎 Find similar documents

Explaining Attention in Transformers [From The Encoder Point of View]
Photo by Devin Avery on Unsplash In this article, we will take a deep dive into the concept of attention in Transformer networks, particularly from the encoder’s perspective. We will cover the followi...
📚 Read more at Towards AI🔎 Find similar documents