hive
Hive is a data warehouse software built on top of Apache Hadoop, designed for data summarization, querying, and analysis. It provides a SQL-like interface, known as HiveQL, which allows users to easily manipulate and query large datasets stored in various file systems. Originally developed by Facebook to handle massive data volumes, Hive simplifies complex data processing tasks by converting queries into efficient map-reduce jobs. Its features include support for different storage types, data modeling, and built-in user-defined functions, making it a valuable tool for data professionals working with big data and unstructured data analysis.

Getting Started With Hive
The aim of this blog post is to help you get started with Hive using Cloudera Manager. Apache Hive is a data warehouse software project built on top of Apache Hadoop for providing data summarization…
📚 Read more at Towards Data Science🔎 Find similar documents

Introduction to Hive
This article focuses on Hive, it’s features, use cases, and Hive queries. Since a lot of DML and DDL queries are very similar to SQL, it can act as a foundation or building block for anyone new to…
📚 Read more at Towards Data Science🔎 Find similar documents

Apache Hive Hacks for a Data Scientist: Part II
Apache Hive is a SQL engine for manipulating big data via SQL commands. If you want to know, more about Hive and why Hive is for Data… Continue reading on Towards AI
📚 Read more at Towards AI🔎 Find similar documents

Limitation of Hive Data Validation
In a big data world, hive is one of the most popular data warehouse tool. Though it comes with some convenient and flexibility features including SQL liked data manipulation language or easily data…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Is it still good to learn Apache Hive?
As the big data world moves towards Apache Spark, Databricks, or Cloud-based Data Warehouses like Amazon RedShift / Snowflake, the general conception is, Hive is an obsolete technology to learn.
📚 Read more at Analytics Vidhya🔎 Find similar documents

Working with Hive using AWS S3 and Python
In this article, I’m going to share my experience of maintaining a Hive schema. This will be useful to the freshers who are willing to step into Big Data technologies. Mainly this will describe how…
📚 Read more at Towards Data Science🔎 Find similar documents

Ultimate Hive Tutorial: Essential Guide to Big Data Management and Querying
Introduction Navigating the labyrinth of big data can be a daunting endeavor, especially when the paths are paved with complex terminology and intricate processes. This is particularly true for Apache...
📚 Read more at Towards Data Science🔎 Find similar documents

Build a Simple To-Do App Using Hive Database
Is Hive the best local storage database? Let’s find out. Continue reading on Better Programming
📚 Read more at Better Programming🔎 Find similar documents

Must-Know Techniques for Handling Big Data in Hive
In most tech companies, data teams must possess strong capabilities to manage and process big data. As a result, familiarity with the Hadoop ecosystem is essential for these teams. Hive Query Language...
📚 Read more at Towards Data Science🔎 Find similar documents

How To Create Your Own Hive SerDe — Hive Custom Data Serialize-Deserialize Mechanism
As mentioned in my earlier blog post, SerDe is an interface which hive use to deserialize (read data from table’s hdfs location then converting it to java object) and serialize data (convert a Java…
📚 Read more at Analytics Vidhya🔎 Find similar documents
Shared External Hive Metastore with Azure Databricks and Synapse Spark Pools
To help structure your data in a data lake you can register and share your data as tables in a Hive metastore. A Hive metastore is a database that holds metadata about our data, such as the paths to…
📚 Read more at Towards Data Science🔎 Find similar documents
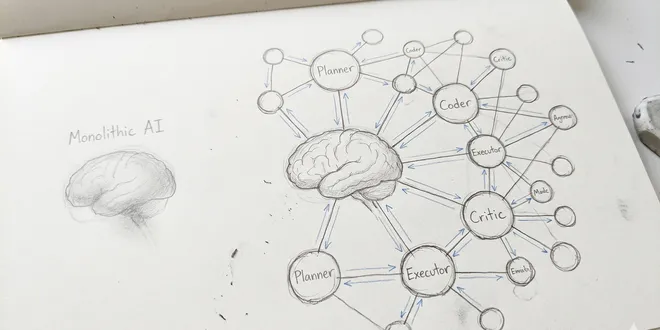
The Hive Mind Unleashed: How Swarms Slash Compute While Improving Reasoning
Why Agent Swarms Are the End of Solo AI Continue reading on Towards AI
📚 Read more at Towards AI🔎 Find similar documents