vanishing&exploding gradient problem
The vanishing and exploding gradient problem is a significant challenge in training deep neural networks. These issues arise during the backpropagation process, where gradients, which guide weight updates, can either diminish to near-zero values (vanishing) or grow excessively large (exploding). When gradients vanish, the model struggles to learn, as weight updates become negligible, leading to stagnation in training. Conversely, exploding gradients can cause drastic weight updates, resulting in unstable training and potential crashes. Understanding and addressing these problems is crucial for developing effective deep learning models, particularly in complex architectures like recurrent neural networks.
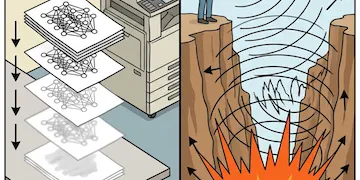
Vanishing and Exploding Gradient
If you’ve ever tried to train a deep neural network and watched the loss stay flat no matter how long you waited, you’ve likely met the twin villains of deep learning: Vanishing and Exploding Gradient...
📚 Read more at Towards AI🔎 Find similar documents

Vanishing & Exploding Gradient Problem: Neural Networks 101
What are Vanishing & Exploding Gradients? In one of my previous posts, we explained neural networks learn through the backpropagation algorithm. The main idea is that we start on the output layer and ...
📚 Read more at Towards Data Science🔎 Find similar documents

Vanishing and Exploding Gradients
In this blog, I will explain how a sigmoid activation can have both vanishing and exploding gradient problem. Vanishing and exploding gradients are one of the biggest problems that the neural network…...
📚 Read more at Level Up Coding🔎 Find similar documents
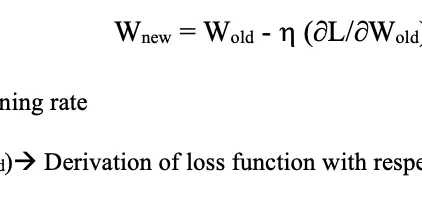
Vanishing and Exploding Gradient Problems
One of the problems with training very deep neural network is that are vanishing and exploding gradients. (i.e When training a very deep neural network, sometimes derivatives becomes very very small…
📚 Read more at Analytics Vidhya🔎 Find similar documents

Exploding And Vanishing Gradient Problem: Math Behind The Truth
Hello Stardust! Today we’ll see mathematical reason behind exploding and vanishing gradient problem but first let’s understand the problem in a nutshell. “Usually, when we train a Deep model using…
📚 Read more at Becoming Human: Artificial Intelligence Magazine🔎 Find similar documents

The Vanishing/Exploding Gradient Problem in Deep Neural Networks
A difficulty that we are faced with when training deep Neural Networks is that of vanishing or exploding gradients. For a long period of time, this obstacle was a major barrier for training large…
📚 Read more at Towards Data Science🔎 Find similar documents
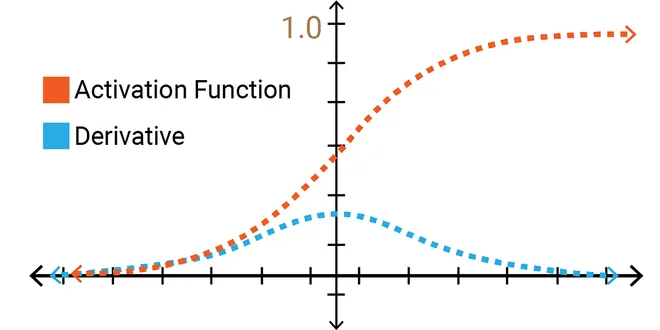
The Problem of Vanishing Gradients
Vanishing gradients occur while training deep neural networks using gradient-based optimization methods. It occurs due to the nature of the backpropagation algorithm that is used to train the neural…
📚 Read more at Towards Data Science🔎 Find similar documents

Alleviating Gradient Issues
Solve Vanishing or Exploding Gradient problem while training a Neural Network using Gradient Descent by using ReLU, SELU, activation functions, BatchNormalization, Dropout & weight initialization
📚 Read more at Towards Data Science🔎 Find similar documents

What Are Gradients, and Why Do They Explode?
Gradients are arguably the most important fundamental concept in machine learning. In this post we will explore the concept of gradients, what makes them vanish and explode, and how to rein them in. W...
📚 Read more at Towards Data Science🔎 Find similar documents

How to Avoid Exploding Gradients With Gradient Clipping
Last Updated on August 28, 2020 Training a neural network can become unstable given the choice of error function, learning rate, or even the scale of the target variable. Large updates to weights duri...
📚 Read more at Machine Learning Mastery🔎 Find similar documents

How to Fix the Vanishing Gradients Problem Using the ReLU
Last Updated on August 25, 2020 The vanishing gradients problem is one example of unstable behavior that you may encounter when training a deep neural network. It describes the situation where a deep ...
📚 Read more at Machine Learning Mastery🔎 Find similar documents

The Vanishing Gradient Problem
The problem: as more layers using certain activation functions are added to neural networks, the gradients of the loss function approaches zero, making the network hard to train. Why: The sigmoid…
📚 Read more at Towards Data Science🔎 Find similar documents