RMSProp
RMSProp, or Root Mean Squared Propagation, is an adaptive learning rate optimization algorithm widely used in training deep learning models. It addresses the limitations of traditional gradient descent methods by adjusting the learning rates based on the moving average of the squared gradients. This approach helps to stabilize the optimization process, particularly in scenarios with steep and narrow loss surfaces. Unlike other algorithms like Adagrad, which can lead to premature convergence due to aggressive learning rate decay, RMSProp maintains flexibility, allowing for more effective training across various problems. Its implementation often includes hyperparameters that can be tuned for optimal performance.

RMSProp
One of the key issues in Section 12.7 is that the learning rate decreases at a predefined schedule of effectively \(\mathcal{O}(t^{-\frac{1}{2}})\) . While this is generally appropriate for convex pro...
📚 Read more at Dive intro Deep Learning Book🔎 Find similar documents

Keras Optimizers Explained: RMSProp
A Comprehensive Overview of the RMSProp Optimization Algorithm Photo by Francesco Califano on Unsplash RMSProp (Root Mean Squared Propagation) is an adaptive learning rate optimization algorithm. Tra...
📚 Read more at Python in Plain English🔎 Find similar documents

RMSprop
Implements RMSprop algorithm. For further details regarding the algorithm we refer to lecture notes by G. Hinton. and centered version Generating Sequences With Recurrent Neural Networks . The impleme...
📚 Read more at PyTorch documentation🔎 Find similar documents

Want your model to converge faster? Use RMSProp!
This is another technique used to speed up Training.. “Want your model to converge faster? Use RMSProp!” is published by Danyal Jamil in Analytics Vidhya.
📚 Read more at Analytics Vidhya🔎 Find similar documents

Gradient Descent With RMSProp from Scratch
Last Updated on October 12, 2021 Gradient descent is an optimization algorithm that follows the negative gradient of an objective function in order to locate the minimum of the function. A limitation ...
📚 Read more at Machine Learning Mastery🔎 Find similar documents

RMSprop Explained: a Dynamic learning rate
Photo by Johnson Wang on Unsplash Introduction: Gradient descent is one of the most fundamental building blocks in all of the machine learning, it can be used to solve simple regression problems or bu...
📚 Read more at Towards AI🔎 Find similar documents
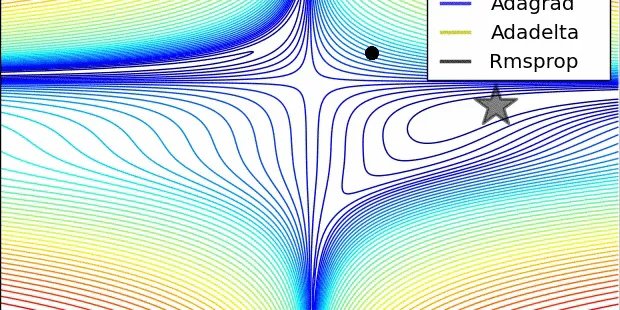
Understanding RMSprop — faster neural network learning
Disclaimer: I presume basic knowledge about neural network optimization algorithms. Particularly, knowledge about SGD and SGD with momentum will be very helpful to understand this post. RMSprop— is…
📚 Read more at Towards Data Science🔎 Find similar documents

{rspm}: easy access to RSPM binary packages with automatic management of system requirements
There are many community projects out there that provide binary R packages for various distributions. You may know Michael Rutter’s legendary c2d4u.team/c2d4u4.0+ PPA, but this situation has been grea...
📚 Read more at R-bloggers🔎 Find similar documents

rOpenSci Champions Program Teams: Meet Cheryl Isabella Lim and Mauro Lepore
We designed the rOpenSci Champions Program with a mentorship aspect. Mentoring plays a significant role in the growth and development of both mentors and mentees alike. In our program, each Champion h...
📚 Read more at R-bloggers🔎 Find similar documents
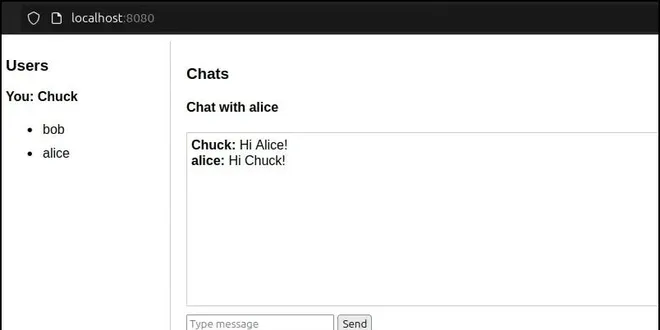
Reactive STOMP Messaging Extension for Quarkus WebSockets
STOMP (Simple Text Oriented Messaging Protocol) is a lightweight protocol for messaging with brokers (see STOMP specification). It is especially suitable for client-side applications having relatively...
📚 Read more at Javarevisited🔎 Find similar documents
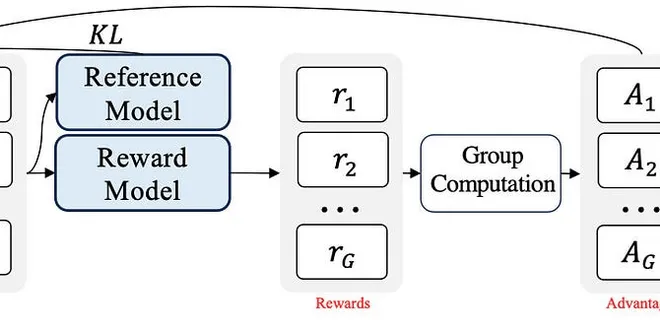
GRPO and DeepSeek-R1-Zero
DeepSeek-R1-Zero training with GRPO 📚 Table of Contents 1. 🔍 DeepSeek-R1-Zero: Why and What? 2. 🏗️ DeepSeek-R1-Zero Model Architecture 3. 🚀 DeepSeek-R1-Zero Training: GRPO 4. ⚖️ Advantages and Dis...
📚 Read more at Towards AI🔎 Find similar documents